
SWE-bench Verified is Flawed Despite Expert Review: UTBoost Exposes Gaps in Test Coverage

This is the second post in the Agentic Benchmark Checklist (ABC) blog series. Written by Yuxuan Zhu and Daniel Kang
SWE-bench has become the “gold standard” for evaluating the coding capability of AI agents. It asks an agent to propose patches for real-world GitHub issues and then evaluates their solutions by running manually-written unit tests. Unfortunately, even carefully crafted unit tests can miss important edge cases.
OpenAI strengthened SWE-bench by asking 93 professional developers to curate a subset, SWE-bench Verified, with revised unit tests. Given all the expert effort involved in verification, is SWE-bench Verified error-free?
Our research shows otherwise: “verified” unit tests are still insufficient in 26/500 tasks in SWE-bench Verified. In our recent ACL paper (code), we introduced a novel technique to identify and fix these insufficient unit tests. The missing unit tests are critical to evaluating performance: When we re-evaluated agent performance using fixed unit tests, the leaderboard rankings changed for 24% agents!1
Why Do Expert-Verified Unit Tests Fall Short? A Motivating Example
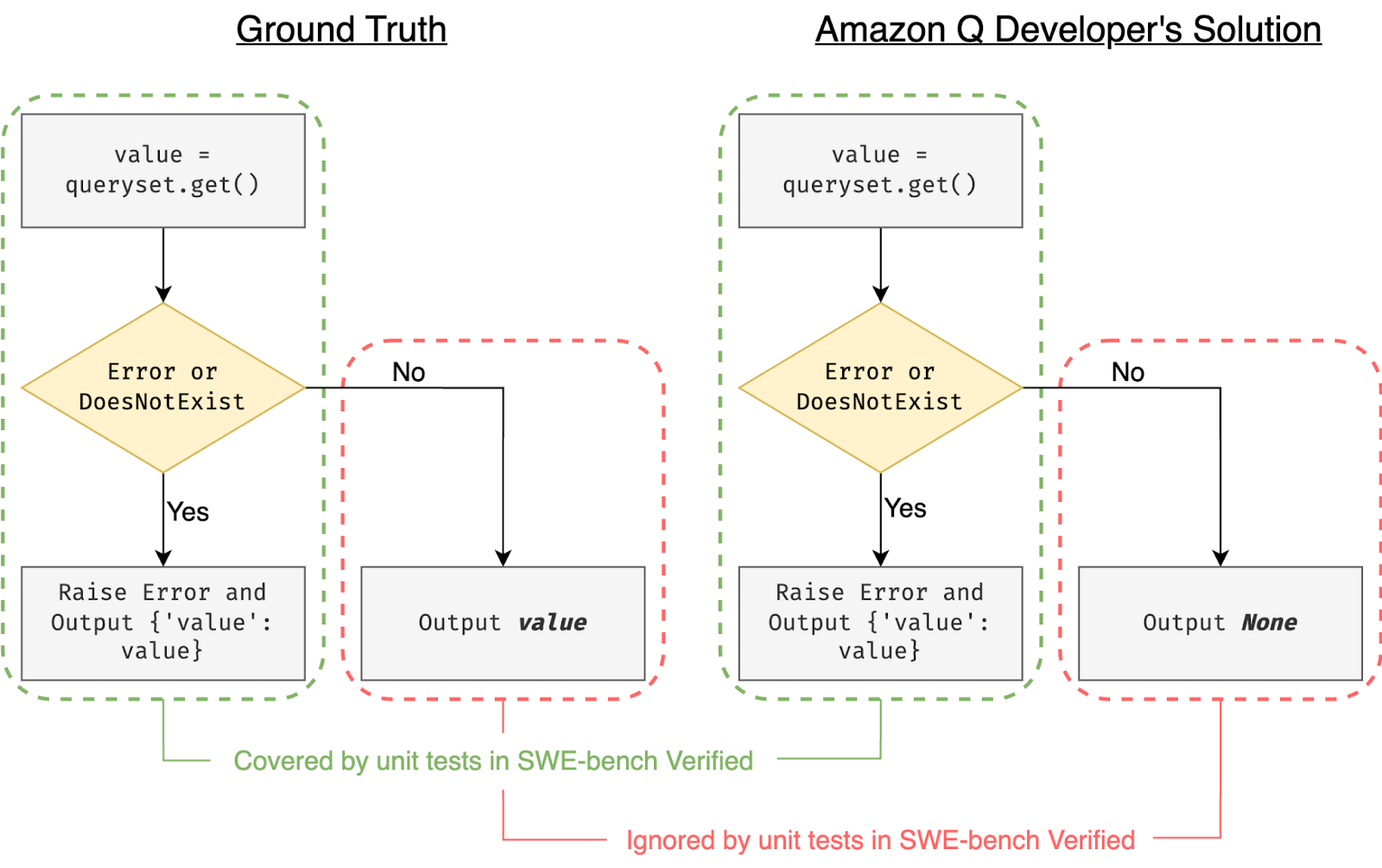
Take PR-13933 from the django project as an example. The agent was supposed to update the code to include the value of an invalid choice in error messages. While the Amazon Q developer correctly updated the error-raising, it also introduced bugs in cases outside error handling, as shown in Figure 1. Because the unit tests only checked the error scenario, the agent’s mistakes were undetected.
As shown, even expert-written unit tests can miss bugs. Therefore, we need a safety net: this is where our new approach, UTBoost, comes in.
UTBoost: The First LLM-Driven Unit Test Generator for Software Projects
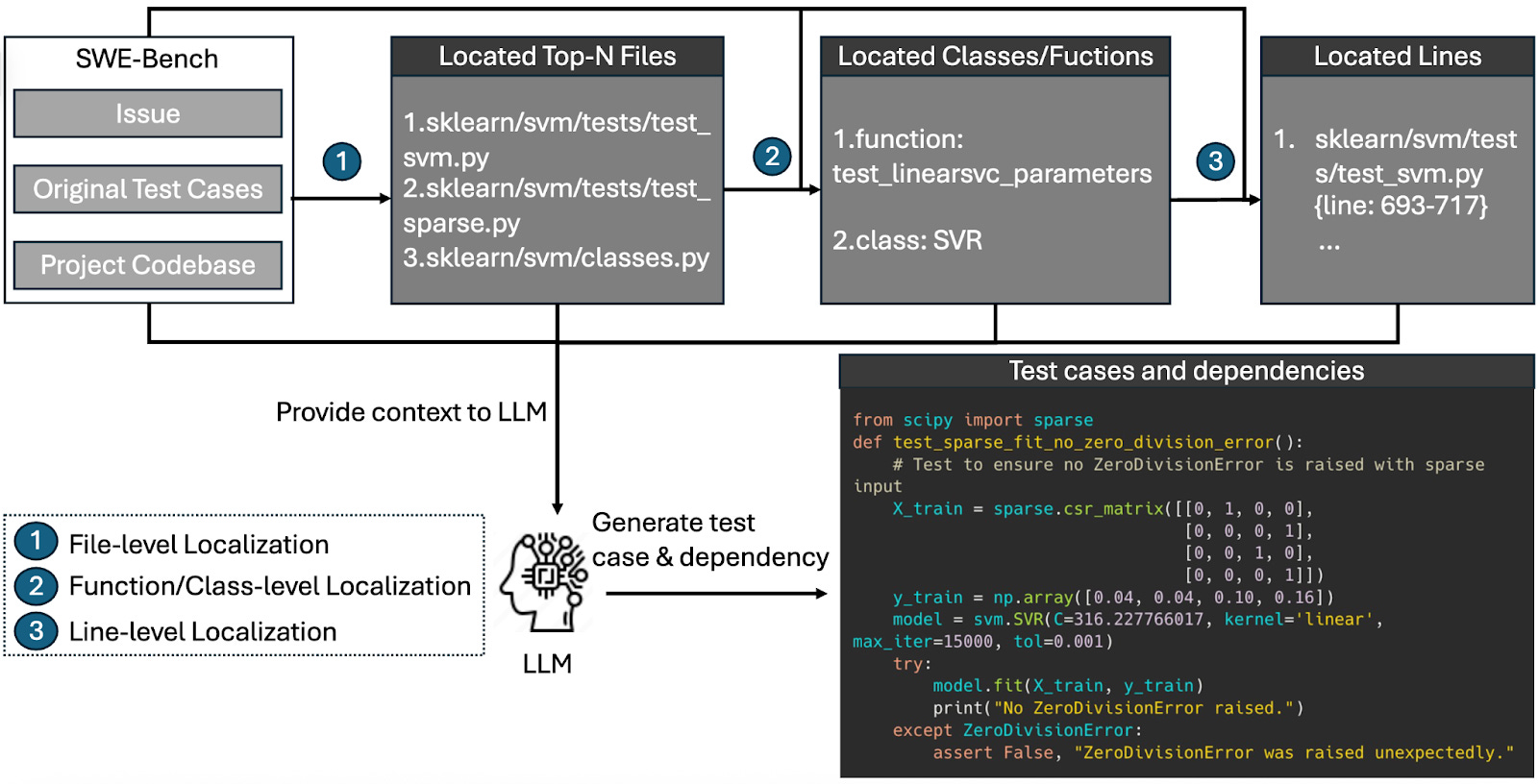
UTBoost uses LLM to automatically generate unit tests for full-scale software projects. However, generating tests for a real codebase is challenging, as real codebases have dozens of files, many dependencies, and diverse codebase structures. UTBoost tackles this complexity in three steps:
File-level: LLM reads the issue description, the existing tests, and a repository summary, then points to the three files most likely involved.
Function/class-level: For each file, it locates the relevant function or class.
Line-level: For each function, LLM highlights the specific lines that matter.
With all of these contexts in place, the LLM writes pytest-style cases that include any necessary dependencies. After we manually verify the correctness of new tests, UTBoost then adds these tests to SWE-bench and reruns the evaluation.
UTBoost Identifies Instances with Insufficient Test Cases
We ran UTBoost on SWE-bench Lite and SWE-bench Verified, using the settings described in our paper. For each incorrect patch identified by UTBoost, two of us independently reviewed it and reached a consensus.
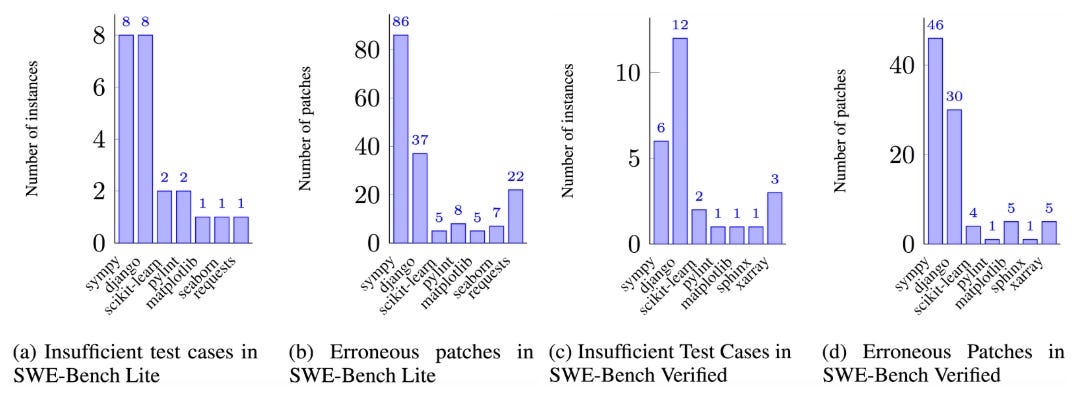
UTBoost identified and augmented unit tests for 23/300 task instances of SWE-bench Lite and 26/500 task instances of SWE-bench Verified. Across all the agent submissions on the leaderboard, these augmented test cases identified 28.4% (SWE-bench Lite) and 15.7% (SWE-bench Verified) more incorrect patches that were previously considered correct.
UTBoost Identifies Erroneous Annotation of Testing Results
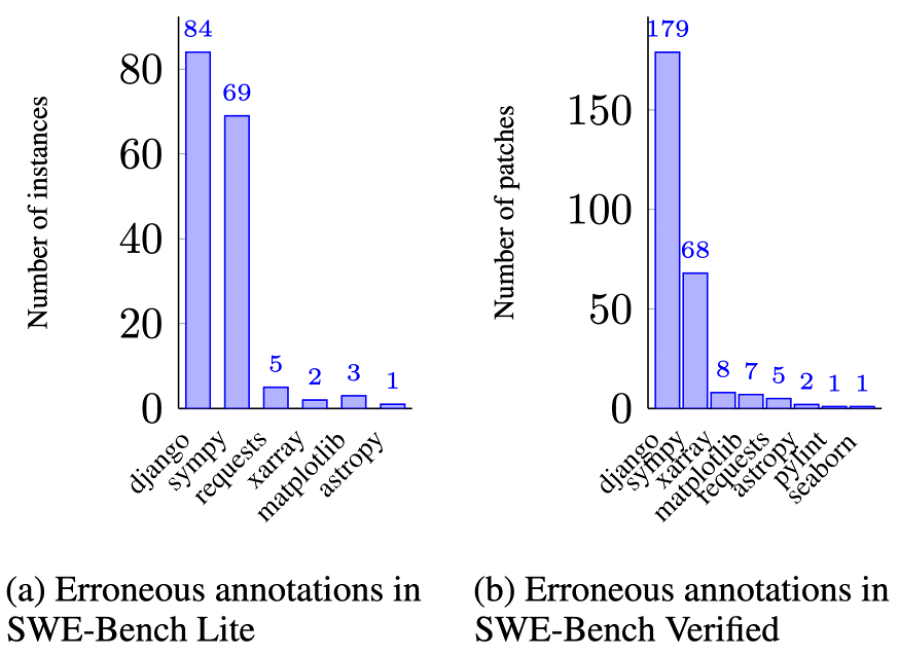
In addition to identifying insufficient unit tests in SWE-bench, UTBoost also helped us find errors in the way test results were annotated by the original parser, such as missed tests or incorrect test names. These errors led to flawed patches being mistakenly considered correct.
After improving the parser, we corrected 54.7% of annotations in SWE-bench Lite submissions and 54.2% in SWE-bench Verified submissions. These corrected annotations lead to 64 (SWE-bench Lite) and 79 (SWE-bench Verified) incorrect patches that were previously labeled correct.
UTBoost Changes the Leaderboard Rankings of SWE-bench
With augmented test cases and the improved parser, we then re-evaluated the agents on SWE-bench’s leaderboards. Across all agent submissions, we identified 176 incorrect patches in SWE-bench Lite and 169 in SWE-bench Verified that were incorrectly evaluated as correct. After fixing the evaluation results, we observed 40.9% and 24.4% ranking changes on the leaderboards of SWE-bench Lite and SWE-bench Verified, respectively.
Conclusion
Software testing has been a challenging problem for decades, and that hasn’t changed just because AI is writing the code. Although UTBoost still does not guarantee error-free coding benchmarks, our results show that augmenting expert-verified tests with LLM-generated tests is a promising path forward.
Given that data noise can affect leaderboard rankings by 24%, we need to rethink whether standalone score comparisons are the best way to compare agents and whether leaderboards are the best way to present the results. We call for a more thorough study in this direction, to build a community with more focus on real progress rather than on the pressure to reach the top of the leaderboard.
UTBoost has been accepted to ACL 2025. We’ve open-sourced the code on GitHub and datasets with fixed unit tests on Hugging Face (Verified, Lite). Give it a try and let us know if you have feedback!
We ran experiments based on the version of the SWE-bench leaderboard and the agents on the leaderboard on December 16, 2024.