
ZKTorch: Open-Sourcing the First Universal ZKML Compiler for Real-World AI

AI has significantly reshaped many aspects of our daily lives. Models like GPT-4o are already being tested to help categorize patients in emergency rooms and to write radiology reports with near-human accuracy. High-stakes domains such as finance and healthcare increasingly rely on AI to approve loans and detect cancer. Yet nearly all of these systems sit behind closed APIs, so neither users nor regulators can verify that an AI model truly delivers its advertised accuracy, safety, or fairness. In principle, providers could publish their weights and inputs so that users could rerun the computation, but that would expose trade secrets and shift an enormous computational burden onto users.
Zero-knowledge machine learning (ZKML) offers a cleaner solution: it enables a model owner to generate a lightweight cryptographic proof for each API output verifying that the inference ran exactly as claimed, without exposing proprietary weights or sensitive data. Moreover, most ZKML proofs are designed to be lightweight so that anyone can verify the proof using standard consumer hardware, such as a laptop. This enables verifiable audits of AI decisions in critical settings:
A hospital can prove that a cancer diagnosis was computed using a certified AI model.
A lender can demonstrate compliance with fairness rules without exposing applicant data.
A regulator can verify that a public chatbot output follows safety policies.
All without revealing the confidential data or model! However, today’s ZKML toolchains still struggle to cover the diverse, large-scale models driving real-world applications. We aim to close that gap.
We're thrilled to open-source ZKTorch: a ZKML framework that efficiently compiles machine learning (ML) models into zero-knowledge proofs (ZKPs). ZKTorch is the first ZKML framework to support every edge model in the MLPerf Inference mobile suite, the ML industry’s flagship performance benchmark. ZKTorch can prove AI models widely used in real-world applications such as large language models (LLMs), convolutional neural networks (CNNs), recurrent neural networks (RNNs), and diffusion models. Below are the key performance highlights of ZKTorch:
Faster proof generation. Up to 3× shorter prover times (e.g., improving GPT-2 inference from >1 hour to ~20 mins).
Smaller proofs. Proof sizes are at least 3× smaller than those produced by specialized protocols (e.g., zkCNN).
Almost unchanged accuracy. Output accuracy differs from the MLPerf baseline by less than 1% after ZKTorch’s quantization, satisfying the benchmark's default 99% accuracy requirement.
In the rest of this post, describe how ZKTorch achieves these performance improvements. We'll conclude with a brief walkthrough to help you start generating your own ZKML proofs (check out our open-source repository).
ZKTorch: a critical step toward practical ZKML
Although ZKML holds great promise, existing methods sit at two impractical extremes: 1) slow, general-purpose proof systems or 2) inflexible specialized protocols limited to particular models. Consider Modulus: generating a proof for a 1.5-billion-parameter LLM (GPT-2-XL) takes over 90 hours, even on 128 threads. By contrast, ZKTorch proves a 6-billion-parameter LLM (GPT-J) in roughly 20 minutes on 64 threads.1 Meanwhile, Halo2-based ZKML provers (e.g., ZKML and EZKL) struggle to handle models larger than about 30 million parameters.
Other systems are highly specialized towards specific classes of models (e.g., zkCNN for convolutions, zkLLM for attention) to improve performance. However, real deployments rarely use a single CNN or LLM in isolation; they chain speech-to-text modules, multimodal blocks, and transformer re-rankers.
ZKTorch bridges this gap with fast, scalable proofs across diverse models.
Technical overview
To understand how ZKTorch achieves this, we’ve provided a technical overview here. For more details about ZKTorch, check out our paper. Feel free to skip to the next section without missing anything!
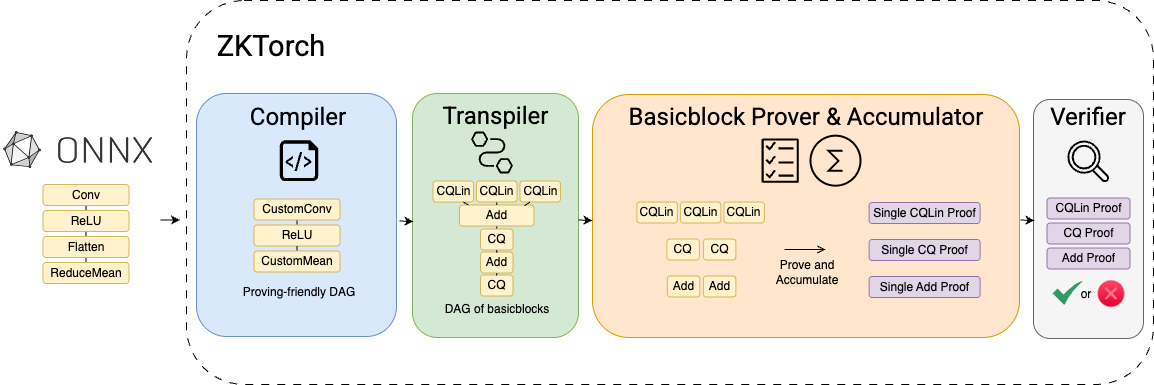
ZKTorch consists of three main components: a compiler, a transpiler, and a library of basic blocks. The compiler rewrites a machine learning model (e.g., an ONNX graph) into a proving-friendly directed acyclic graph, where each node represents an ML operation. For example, the GPT-J model provided by MLPerf Inference uses eight ONNX nodes to represent a single GeLU activation, requiring more than five lookup arguments to prove (each lookup allows us to prove that the elements of a committed vector come from a much bigger committed table). Our compiler consolidates these nodes into a single GeLU node, reducing the proof overhead to just one lookup.
The transpiler then replaces each node with an optimized composition of basic blocks, which are zero-knowledge protocols tailored to each operation. For instance, matrix multiplication can be transpiled into a recent optimized protocol CQLin, which can prove the result of matrix multiplication in O(n) time when one matrix is fixed. Non-linearities such as GeLU are handled with an optimized lookup argument CQ, whose proving time is independent of the lookup table size. (For more details on these protocols, please check out our previous post). With basic block support for all 61 MLPerf v4.1 layers, ZKTorch can decompose models ranging from CNNs (e.g., ResNet-50) to LLMs (e.g., GPT-J and GPT-2) into thousands of small proofs.
Although each individual proof is small, collectively they can result in a large overall proof size. To address this, ZKTorch employs an accumulation scheme that folds multiple proofs from the same basic block into a single compact proof. Our accumulation scheme extends Mira by making it parallelizable. This parallel extension significantly accelerates the folding process, reducing the proving time for GPT-J from 8,662 seconds to just 1,397 seconds. By folding all proofs of the same basic block type into a single accumulator instance, the prover produces one lightweight proof whose size and verification time remain nearly constant, regardless of the model’s depth. In practice, this brings down GPT-2 proving time from over an hour (ZKML) to just 10 minutes, and reduces a ResNet-50 proof from 1.27 GB (Mystique) to 85 KB.
🚀 Quick Start: Try ZKTorch in Minutes
Getting started with ZKTorch is straightforward. Follow two simple steps:
Step 1. Install Rust (skip if already installed)
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | shStep 2. Clone and run ZKTorch
git clone https://github.com/uiuc-kang-lab/zk-torch.git
cd zk-torch
rustup override set nightly
cargo run --release --bin zk_torch --features fold -- config.yamlAfter cloning the repository, we’ve provided a sample configuration `config.yaml`, which defines file paths (e.g., ONNX model, input data, and proof) and scale parameters. For example, the `scale_factor_log` entry determines how floating-point numbers are converted into fixed-point integers for proof generation; for instance, setting `scale_factor_log = 10` means a value `x` will be encoded as `round(x × 210)`. Easily experiment with your own ML models by replacing the included ONNX file and the corresponding input file defined in `config.yaml`.
If you plan on changing the example configuration file, the powers of tau file needs to be compatible with the configuration settings.
Check out ZKTorch today!
ZKTorch represents a significant step toward making practical and usable ZKML. We're excited for developers, researchers, and industry professionals to explore, experiment, and expand upon ZKTorch. If you’re interested in contributing to ZKTorch, please reach out via our Telegram group or by email!
Check out our paper and code on GitHub. We also look forward to learning from your ideas for how to build with ZKTorch. If you’d love to share your ideas with us, welcome to join our Telegram group.
Written by ZKTorch authors
This proving number, as with the Modulus proving number, is on a single output token.