
Human Data is (Probably) More Expensive Than Compute for Training Frontier LLMs
This blog post is written by Yuxuan Zhu and Daniel Kang

Post-training techniques (e.g., supervised fine-tuning and reinforcement learning with verifiable rewards) are crucial to recent advances in LLMs. Unlike pre-training, post-training relies heavily on annotated data provided by humans, often requiring expert input. Fine-tuning with reinforcement learning, the core technique powering today’s most advanced reasoning models, demands not only high-quality data but also verifiable answers.
“Scale AI expects to more than double sales to $2 billion in 2025. The startup generated revenue of about $870 million last year,” reported by Bloomberg.
The incredible demand for high-quality human-annotated data is fueling soaring revenues of data labeling companies. In tandem, the cost of human labor has been consistently increasing. We estimate that obtaining high-quality human data for LLM post-training is more expensive than the marginal compute itself1 and will only become even more expensive. In other words, high-quality human data will be the bottleneck for AI progress if these trends continue.
Data Labeling Company Revenues Outweigh (Marginal) AI Training Costs
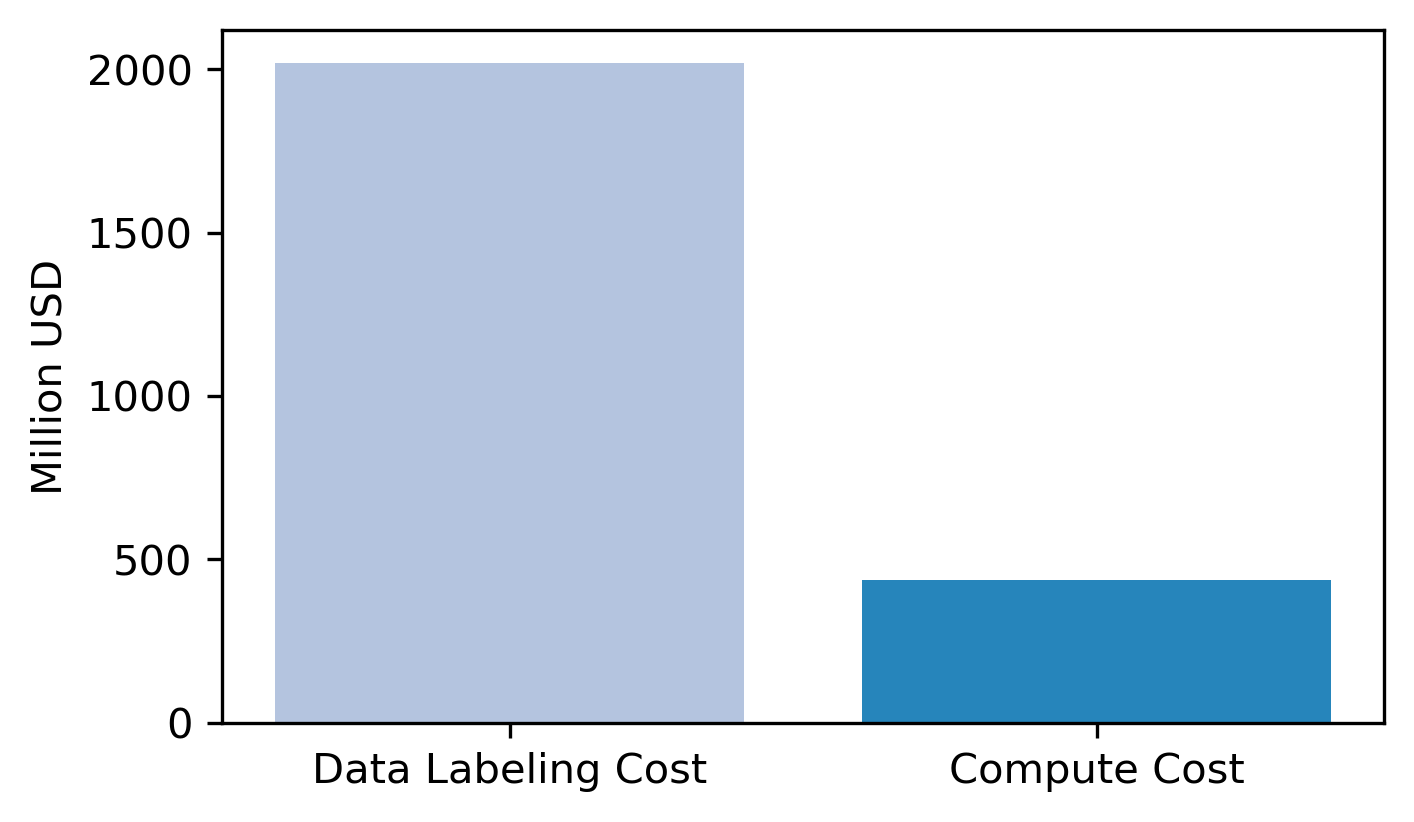
To assess the proportion of data labeling costs within the overall AI training budget, we collected and estimated both data labeling and compute expenses for leading AI providers in 2024:
Data labeling costs: We collected revenue estimates of major data labeling companies, such as Scale AI, Surge AI, Mercor, and LabelBox.
Compute costs: We gathered publicly reported marginal costs of compute2 associated with training top models released in 2024, including Sonnet 3.5, GPT-4o, DeepSeek-V3, Mistral Large, Llama 3.1-405B, and Grok 2.
We then calculate the sum of costs in a category as the estimate of the market total. As shown above, the total cost of data labeling is approximately 3.1 times higher than total marginal compute costs. This finding highlights clear evidence: the cost of acquiring high-quality human-annotated data is rapidly outpacing the compute costs required for training state-of-the-art AI models.
Data Labeling Companies are Dramatically Increasing Revenue
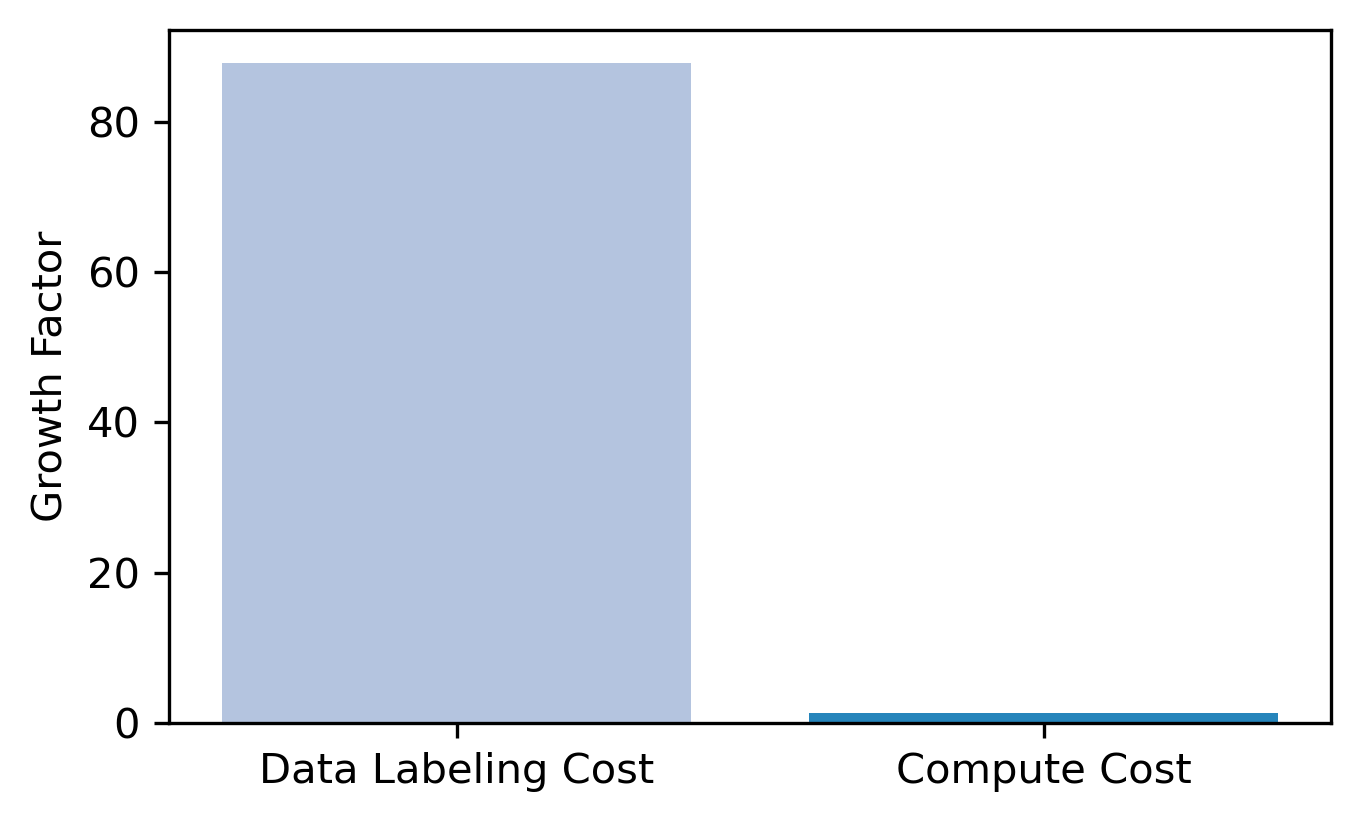
Next, we examined the growth trajectory of data labeling costs from 2023 to 2024. To do this, we collected estimates of the total data labeling and marginal compute costs for training released frontier LLMs for both years and compared the results. As shown in Figure 2, data labeling costs surged with a remarkable growth factor of 88, while compute costs increased by only 1.3 times. Given the rising importance of high-quality human data for reinforcement fine-tuning and cheaper AI accelerators, we expect data labeling costs to continue growing rapidly, while the rate of increase in compute costs may slow in the coming years.
It’s important to note that the growth factor is largely driven by Mercor, which is reportedly the fastest company ever to grow from $1M to $100M ARR. We don’t think these growth rates will continue into the future but think it points towards rapid growth of human data.
Lessons Learned from MiniMax-M1 and SkyRL-SQL
We conclude our analysis with two case studies, MiniMax-M1 and SkyRL-SQL. These models fully describe their training costs and data amounts, so we can analyze both the training costs and data costs.
Efficient RL Scaling in MiniMax-M1. With a training compute cost of just $500K, MiniMax-M1 matches or even outperforms Claude Opus 4 on benchmarks. While explicit data labeling costs are not detailed, MiniMax’s report emphasizes the importance of a “carefully designed curriculum” built from “carefully selected, high-quality” data with about 140K samples for RL training.
If we estimate that a data point would cost $100 (if it were labeled by a human, as opposed to being distilled from another model), the data costs would be $14M in data labeling, 28 times higher than the marginal compute cost for training.
SkyRL-SQL trained a model for text-to-SQL tasks that matches GPT-4o and o4-mini. To achieve this result, SkyRL-SQL uses a novel multi-turn RL algorithm, which teaches the model to iteratively correct its own errors and solve problems step by step. SkyRL-SQL only costs $360 in compute for training. By contrast, we estimate that producing the 600 high-quality annotations cost about $60,000, which is approximately 167x the training compute expense.
Even if our data cost estimates are an order of magnitude off, they would still be ~3x and ~17x more expensive than the compute!
Conclusions and Recommendations
While scaling pretraining data quantity and compute has driven remarkable breakthroughs in the past few years, this strategy has seemingly plateaued with the limits of static data. The rise of RL, which depends on high-quality human-annotated data, has shifted the focus from simply scaling data volume to prioritizing data quality. However, this approach introduces its own challenges, notably the rapidly increasing costs of large-scale data annotation.
Our estimates suggest that high-quality human data is the primary marginal cost of training frontier LLMs. Combined with the performance improvements coming from reinforcement learning, we believe these trends have major implications for understanding AI progress and potentially for policy.
Our blog post will not answer all questions on the impact of high-quality human data on AI progress. As a first step, we recommend that organizations that track inputs to AI should also track the cost of human data used to train frontier models.
Stay tuned for more analysis and recommendations in the future!
In marginal costs for the final training runs.
We only consider the marginal costs of compute, which does not include capital expenditures such as building the compute infrastructure or the R&D that goes before training.
Interesting… data creation is marginal given others will distill it making that data less valuable over the long term?
I think that it's helpful to see a characterisation of the quality and cost of synthetic data.