
SODIUM: From Open Web Data to Queryable Databases

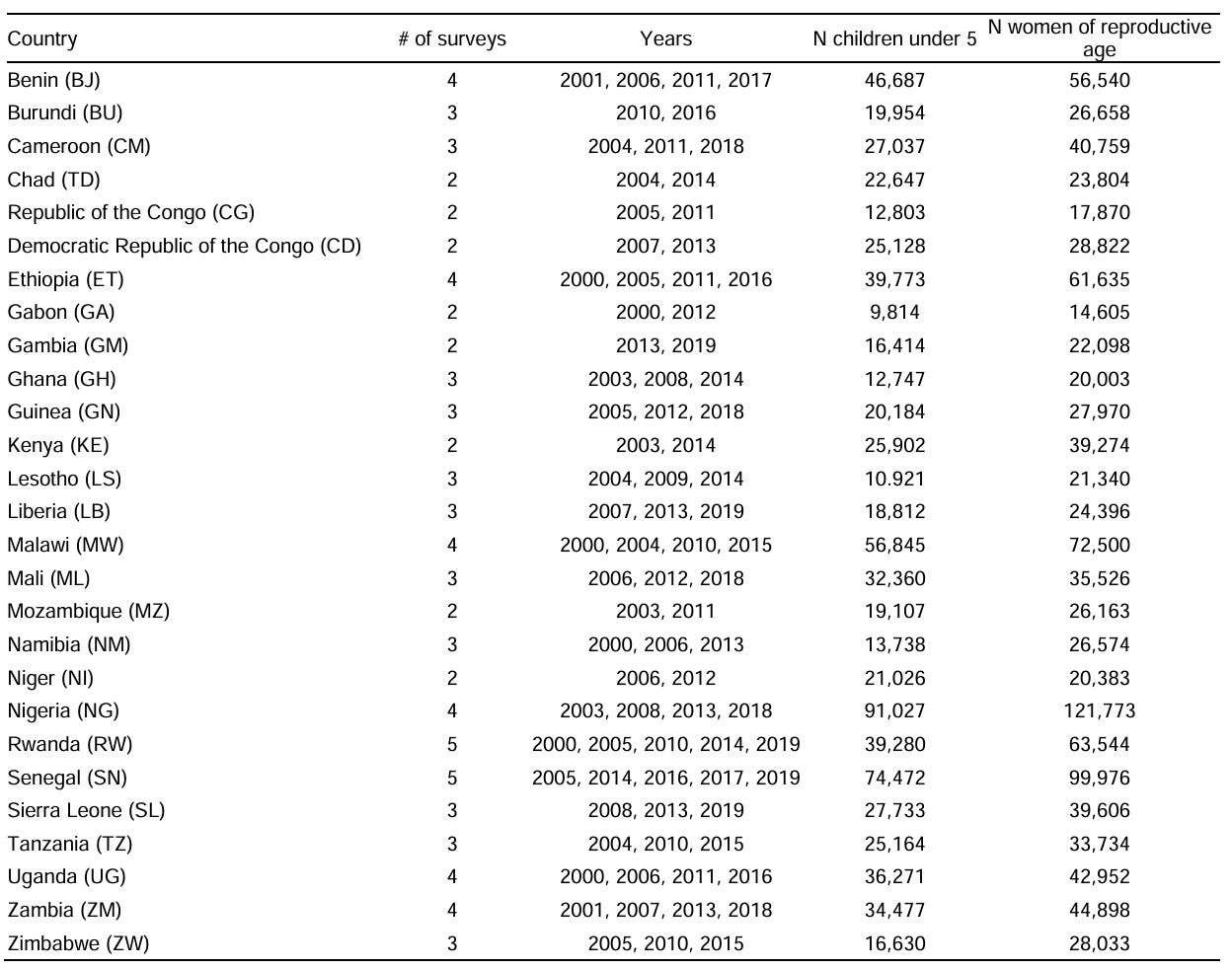
In research workflows using public data, answering a single analytical question requires collecting and organizing data from many different web sources. For example, a demographic researcher studying children under five in polygynous households in sub-Saharan Africa needs to construct a table indexed by country, with columns describing survey coverage and key demographic statistics (as we show below). Although the data are publicly available on the Demographic and Health Surveys (DHS) website, retrieving them requires navigating multiple layers of the site, locating the relevant datasets from different surveys, and manually aggregating values across years and sources. Thus, before any real analysis can begin, researchers often spend significant time searching for data, extracting values, and organizing them into structured tables.
In our paper, we formalize this process as SODIUM, where the open web is treated as a latent database that can be systematically materialized. Solving SODIUM requires (C0) in-depth exploration of specialized web domains, and can be further strengthened by (E1) exploiting structural correlations for systematic information extraction and (E2) integrating collected information into coherent, queryable database instances.
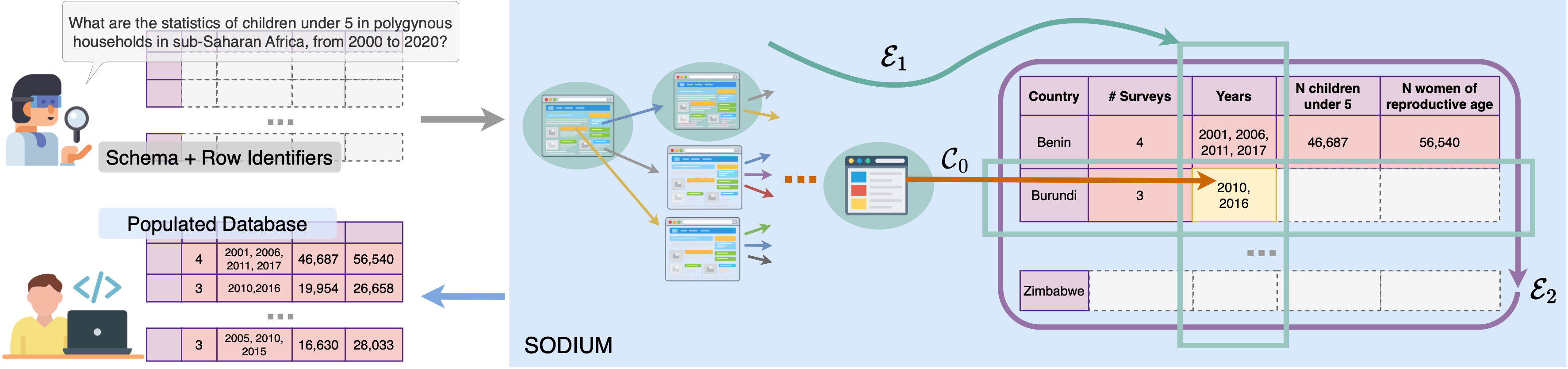
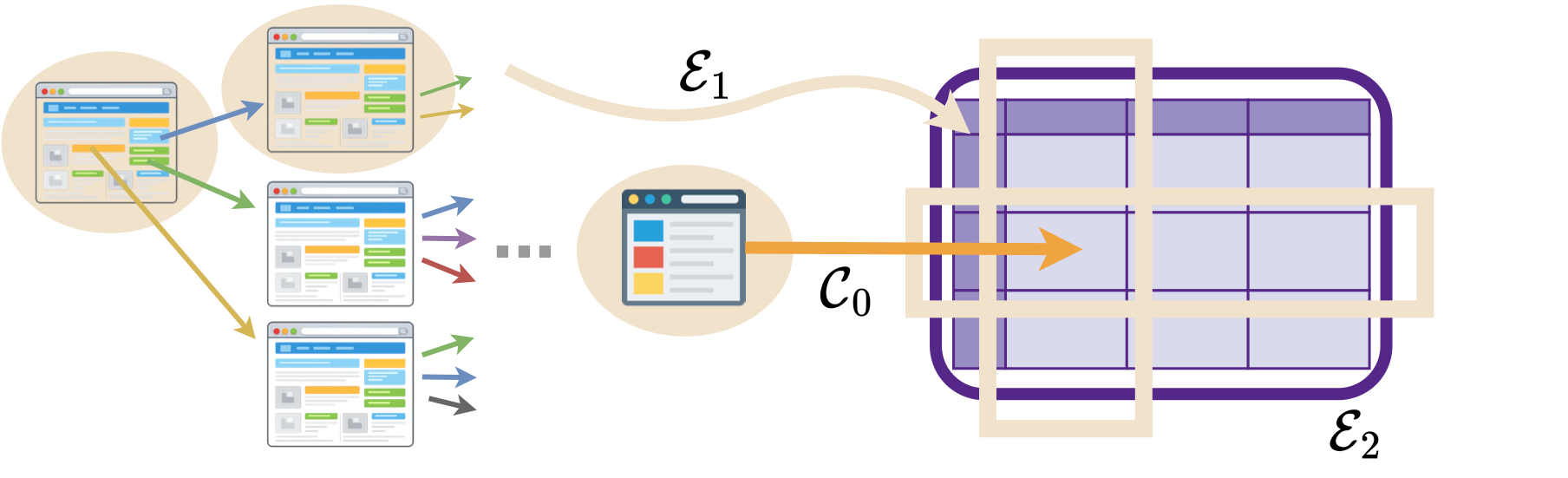
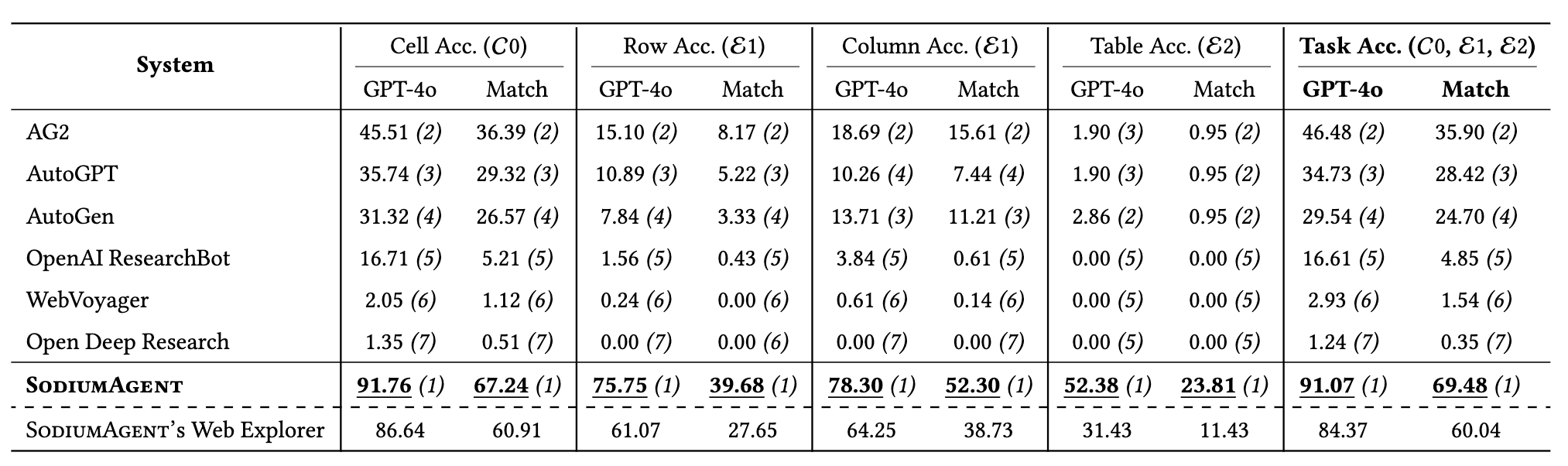
None of the existing systems fully realize C0, E1, or E2, as reflected in their limited performance. Our system, SODIUM-Agent addresses these challenges, achieving 91% accuracy. Read on for details on how we measured and built SODIUM and SODIUM-Agent!
SODIUM tasks are challenging
To quantitatively evaluate existing AI agents on SODIUM tasks, we constructed SODIUM-Bench, a benchmark consisting of 105 analytical queries derived from 48 published research papers across 6 domains.
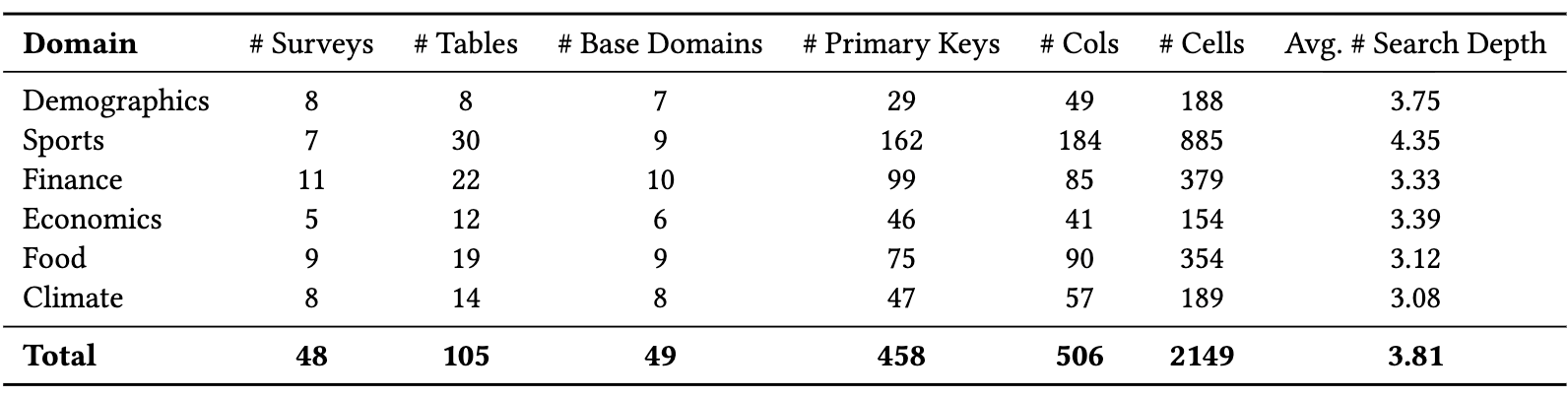
In each SODIUM-Bench task, the system takes as input:
a natural language analytical query describing the research objective of the paper;
a base domain specifying the authoritative data source (i.e., the official homepage of the relevant organization or data portal);
a target relational schema specifying a designated primary key and a set of attributes, together with a set of primary key values defining the rows to be instantiated.
The system is tasked with populating the table.
We evaluate 6 state-of-the-art agents with advanced web search capabilities on SODIUM-Bench. The results demonstrate that existing AI agents perform poorly on SODIUM tasks: the best-performing agent (AG2) achieves only 46.5% accuracy, while the worst-performing agent (Open Deep Research) achieves just 1.24%.
SODIUM-Agent achieves promising performance on SODIUM tasks
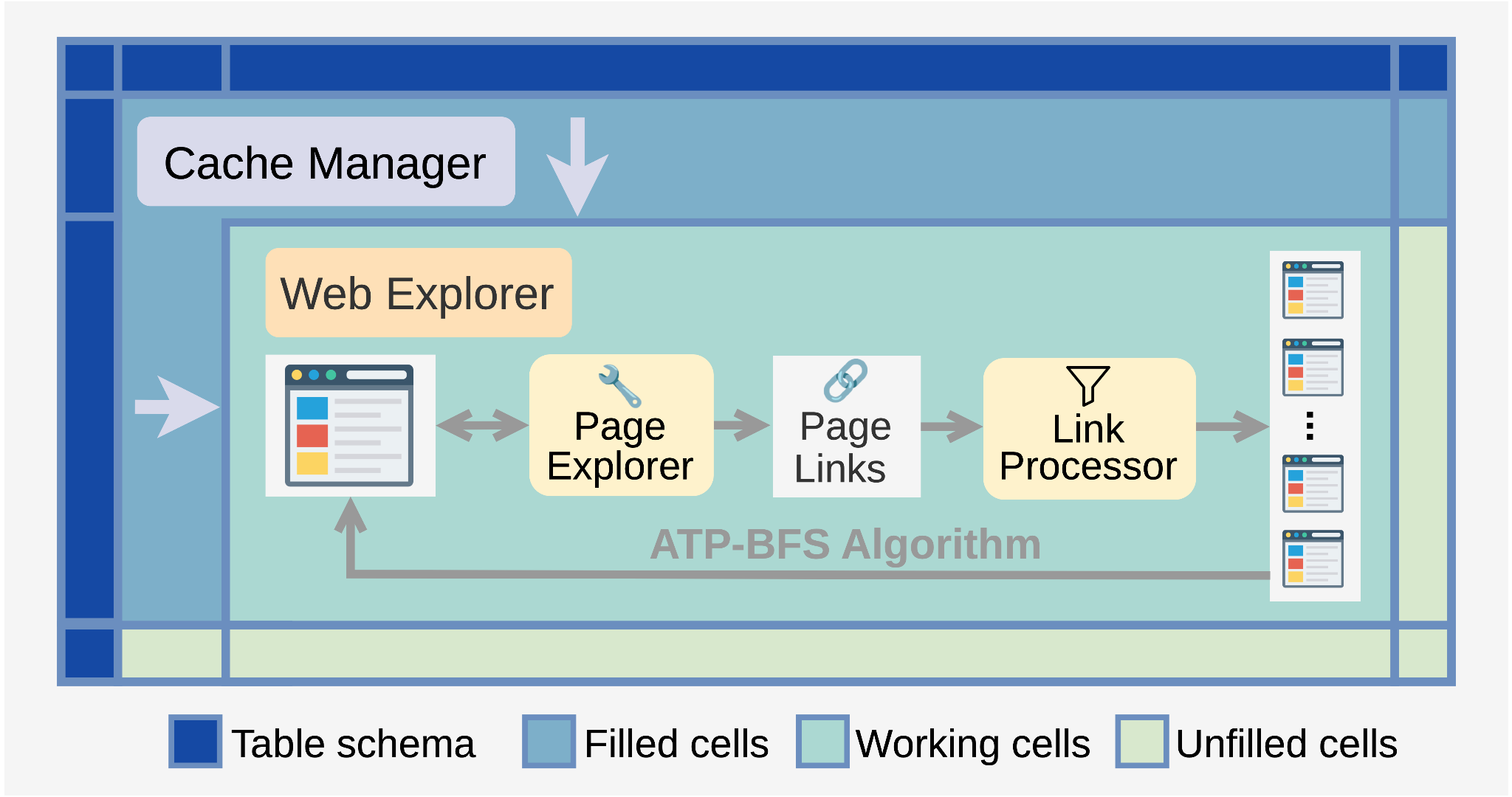
To address this gap, we develop SODIUM-Agent, a multi-agent system composed of a web explorer and a cache manager.
For the web explorer, we design the augment-then-prune breadth-first (ATP-BFS) web exploration algorithm, an agentic web exploration algorithm that serves as the backbone of the web explorer by conducting deep and comprehensive exploration on all visited webpages. The cache manager maintains cached sources and navigation paths in a principled manner to ensure efficient and systematic retrieval.
SODIUM-Agent achieves 91% accuracy on SODIUM-Bench, significantly outperforming SOTA AI agents across diverse dimensions.
Why SODIUM Matters
Real-world analytical tasks in scientific research require collecting data scattered across numerous webpages and datasets. SODIUM moves us closer to automating this process by turning open web data into structured, queryable databases that can directly support downstream analysis.
Check out our paper and code, as well as a demo! And reach out to us if you’re interested in using SODIUM.