
Reinforcement Post Training Generalizes Poorly Out-of-Domain

Large language models (LLMs) have made tremendous strides across a wide range of domains, from structured reasoning tasks like math and code to general reasoning tasks such as legal reasoning, financial problem solving, and medical question answering. A major catalyst behind these advances has been reinforcement post training (RPT), which enables models to achieve and sometimes even outperform top human performers in programming competitions and mathematics contests.
However, a key requirement for models is that they must reliably handle scenarios that differ from their training data. This raises a key question: does RPT generalize effectively across tasks and domains?
So far, answers to this question have been inconclusive. Most evaluations focus on in-domain performance, using RPT models trained on mixed-domain data and evaluated on benchmarks closely aligned with their training distribution. These setups introduce confounding factors that obscure our understanding of RPT's true generalization ability.
To address this gap, we designed and conducted a unified evaluation framework that isolates and tests RPT's cross-domain generalizability more rigorously. Our results show that while RPT is highly effective within its training domain, its benefits do not consistently transfer to out-of-domain tasks. This highlights the need for a more nuanced understanding of how post-training mechanisms generalize across domains.
Measuring RPT Generalization
To systematically study the generalizability of RPT while eliminating confounding factors from entangled training data, we first divide the RPT training data into three major domains and then design a unified evaluation framework spanning 16 benchmarks.
Math: GSM8K, MATH-500, AIME 2024, and AMC 2023
Code: MBPP, HumanEval, BigCodeBench, LiveCodeBench, USACO, Codeforces, and Aider Polyglot
Knowledge-Intensive Reasoning: PubMedQA, MedQA, TabFact, LegalBench, and FinBench
Using this framework, we conducted two complementary studies: an observational study that examines existing models with public RPT data, and an interventional study where we fine-tune models on specific domains to directly evaluate their cross-domain generalization. In both settings, we evaluate RPT's effectiveness by comparing performance gains over base models across different domains.
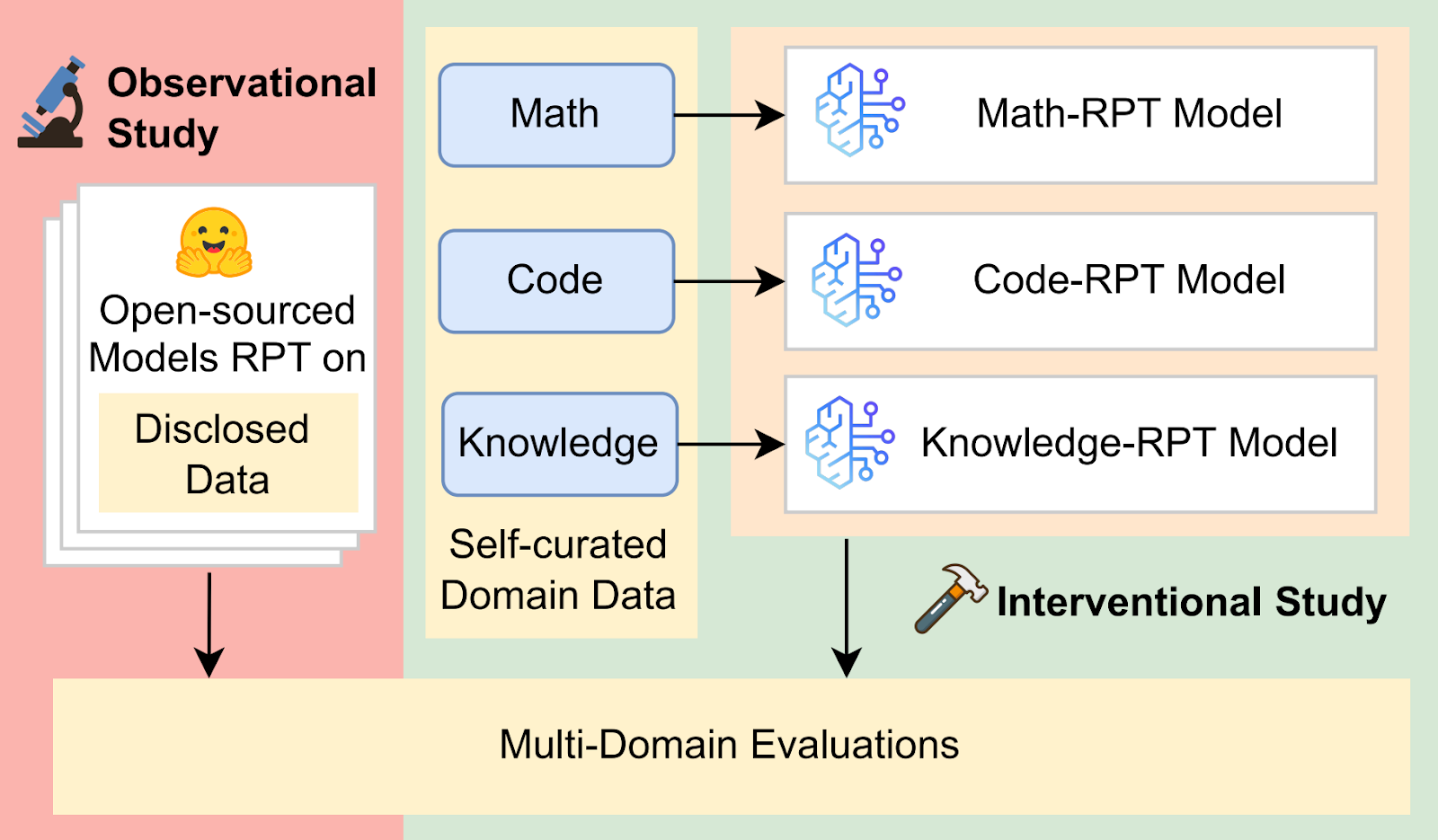
Observational Study
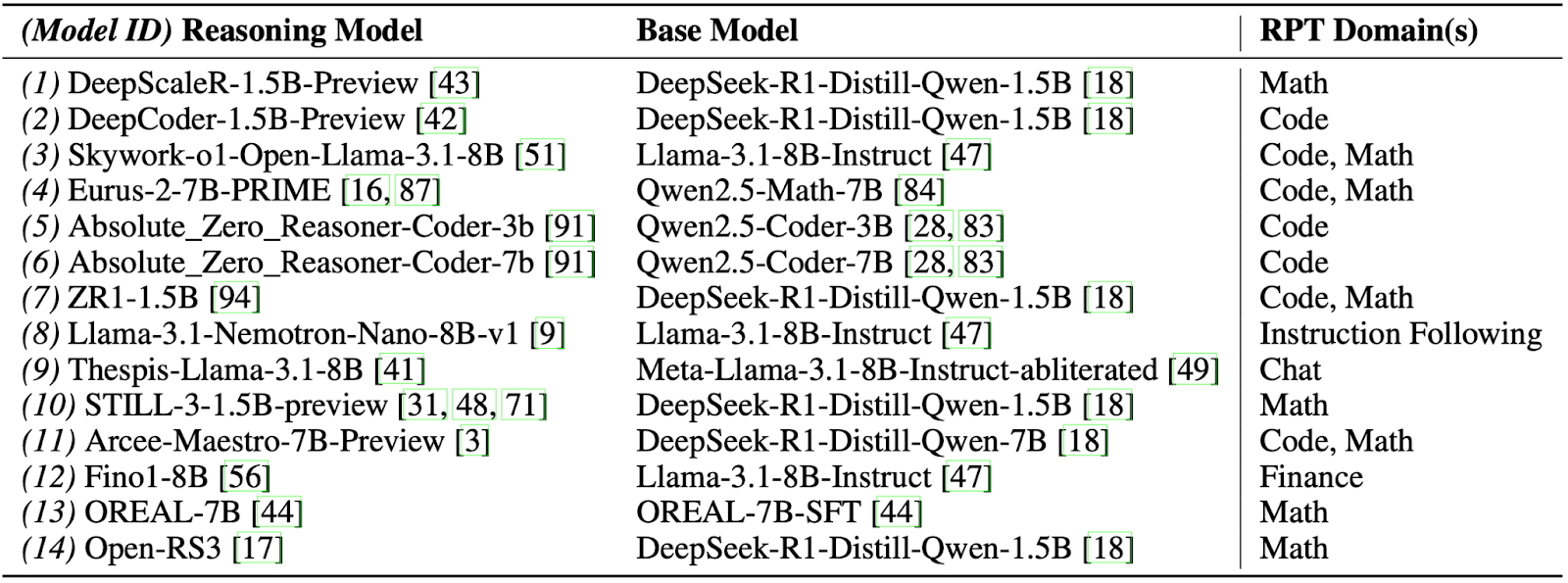
We evaluate 14 open-weight RPT models, as we show in the table below, with publicly disclosed training data, alongside their respective base models. These models span domains like math, code, law, finance, and medicine. This allows us to assess whether fine-tuned gains persist when applied to unseen domains.
Interventional Study
To remove confounding factors from mixed-domain training, we fine-tune LLMs from scratch using reinforcement learning on math, code, and knowledge-intensive reasoning data, respectively. We then evaluate their performance on both in-domain and out-of-domain tasks to understand how fine-tuned capabilities transfer. We refer to models fine-tuned on the corresponding domains as Math-RPT, Code-RPT, and Knowledge-RPT throughout the following text and figures.
Our Findings
We illustrate the three key findings from our empirical analysis as follows.
Finding 1: RPT Gains Are Mostly In-Domain
In our observational analysis, we find that RPT leads to notable improvements only within the domains it was trained on. Across the 14 models we studied, pass@1 accuracy increased by 3.57% on in-domain tasks, but dropped by 1.48% on out-of-domain tasks.
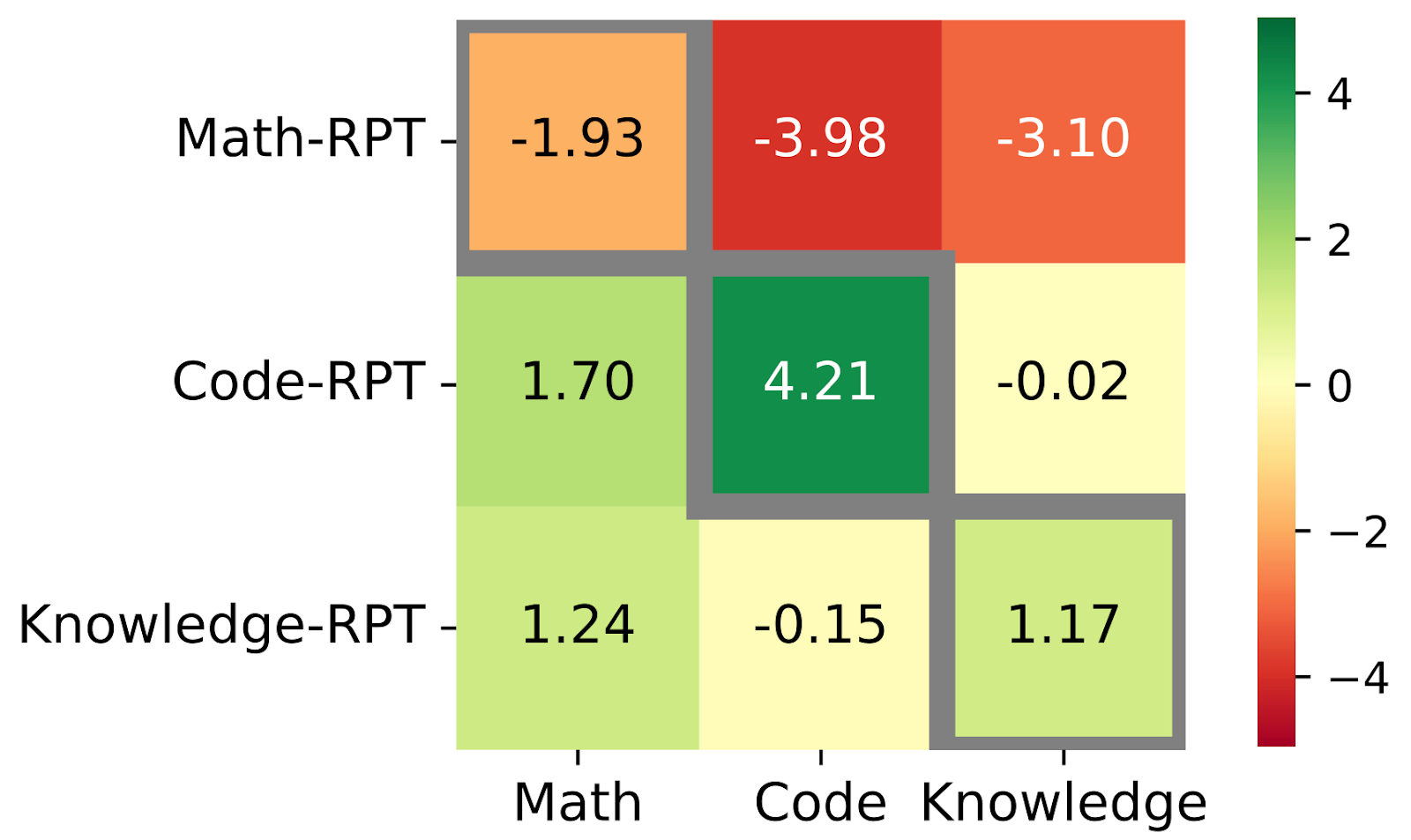
The interventional study reinforces this finding. As we demonstrate in the figure below, none of the models fine-tuned on a single domain exhibited statistically significant gains on out-of-domain benchmarks. On the contrary, both the Math-RPT and Code-RPT models show statistically significant performance drops on out-of-domain tasks. The Knowledge-RPT model also failed to generalize beyond its training data, showing no meaningful gains on unseen domains.
Finding 2: Structured Domains Like Math and Code Mutually Generalize
We observe strong mutual generalization between math and code. In our observational study, Math-RPT models improved by 2.18% on math and 4.77% on code tasks, and Code-RPT models improved by 9.49% on code and 15.44% on math tasks.
In both cases, models often performed even better on the unseen structured domain, suggesting shared underlying reasoning patterns between math and code that RPT is able to exploit.
Finding 3: Structured Skills Do Not Transfer to Knowledge-Intensive Reasoning
While math and code fine-tuning transfer well between each other, these structured reasoning skills do not generalize to unstructured or knowledge-intensive reasoning domains. In our observational study, structured-domain models showed only a −0.27% average change in pass@1 on knowledge-intensive reasoning domain tasks, compared to 11.08% and 5.82% gains on math and code respectively.
The interventional study confirms this trend. As we demonstrate in the figure above, the Math-RPT and Code-RPT models both underperform on knowledge-intensive reasoning tasks, despite showing robust gains in their respective domains. These findings indicate that while RPT is highly effective in capturing domain-specific reasoning, it fails to adapt to tasks requiring broader, more heterogeneous reasoning patterns.
Conclusion: RPT Is Powerful but Narrow
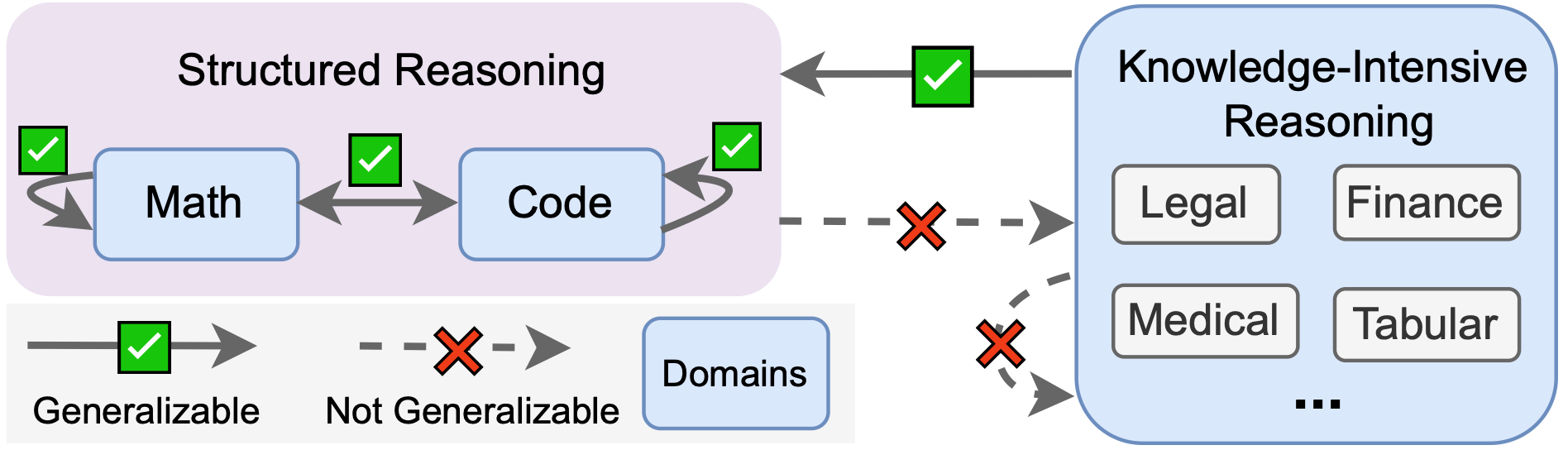
In this work, through both observational and interventional studies, we consistently find that while RPT produces substantial improvements within training domains, its generalization to unseen domains is limited, as we summarize in the figure below. In particular, while there is evidence of cross-domain transfer between structured domains like math and code, there is little evidence of transfer to unstructured domains.
Read our paper for more details! And stay tuned for more thoughts on implications for future progress.