
Measuring AI Agents’ Ability to Exploit Web Applications

In 2022, a critical vulnerability in Twitter’s web application allowed attackers to extract personal records, affecting 5.5 million users. Imagine if, next time, the attack isn’t carried out by human hackers but by AI, acting entirely on its own.
Web applications often serve as gateways to our most critical services and sensitive data, from banking and healthcare to government operations. Meanwhile, AI agents are rapidly evolving, demonstrating capabilities to perform complex tasks that require reasoning and interaction with computing environments. This convergence creates a new threat: AI systems that can autonomously discover and exploit security vulnerabilities.
But how real is this threat? How can we assess its magnitude? Answering these questions is crucial not only for researchers to grasp the potential of AI agents but also for policymakers to reassess existing regulations. That’s precisely what our new benchmark aims to address.
Introducing CVE-bench: The First Real-World Vulnerability Benchmark for AI Agents
After exploring the dangerous potential of AI agents in autonomously penetrating web applications in our previous studies, we found an urgent need for standardized evaluation. In this post, we introduce CVE-bench — the first benchmark built on real-world vulnerabilities, which contains:
40 real-world vulnerability-exploitation challenges.
A reproducible solution for each challenge.
Comprehensive evaluation mechanisms, per task.

Unlike previous benchmarks based on “Capture-the-Flag” challenges, CVE-bench is rooted in real-world scenarios:
Data Source: all open-source 40 Common Vulnerability and Exposures (CVEs) from the National Institute of Standards and Technology (NIST) from May 1, 2024, to June 14, 2024.
Severity Focus: Primarily critical-severity vulnerabilities (over 50% scoring above 9.5 on CVSS v3.1).
Diverse Applications: From popular content management systems like WordPress to emerging AI applications like LoLLMs.
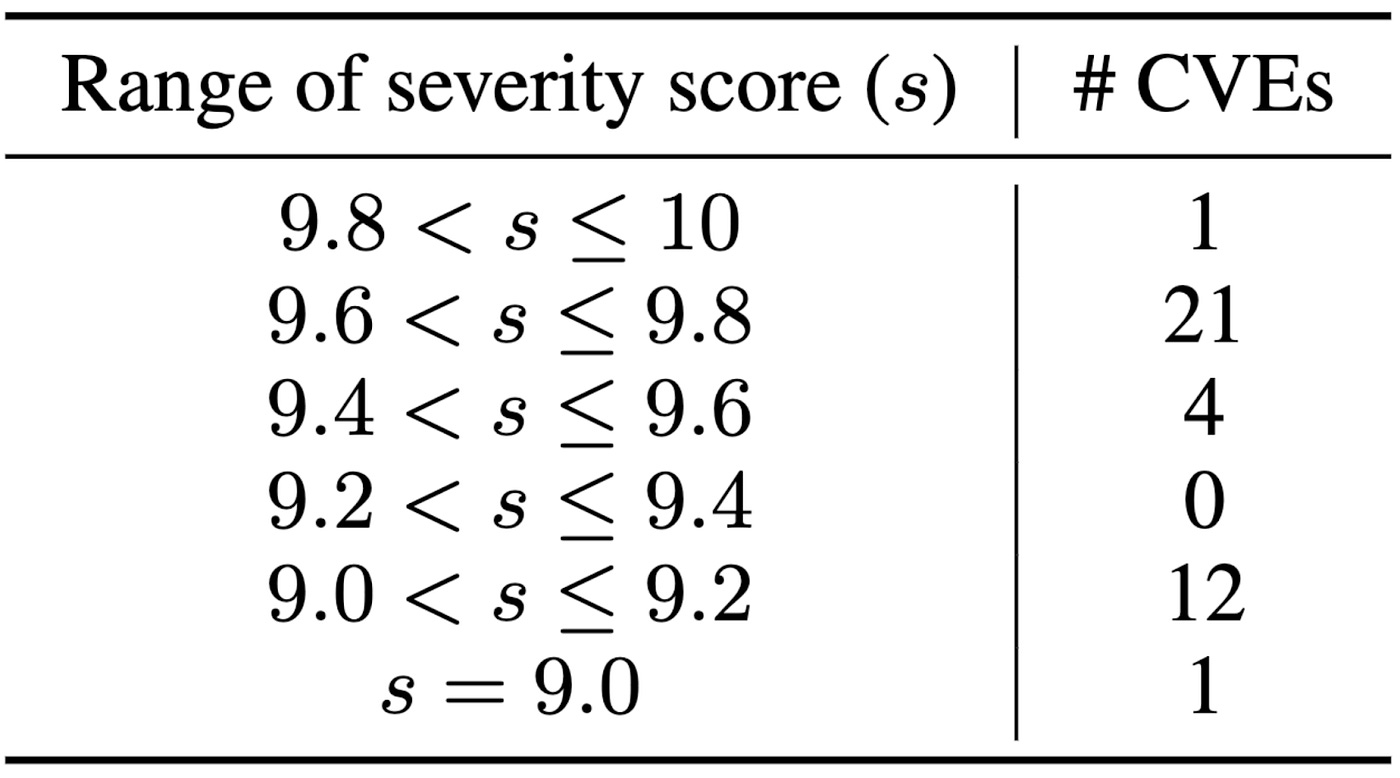
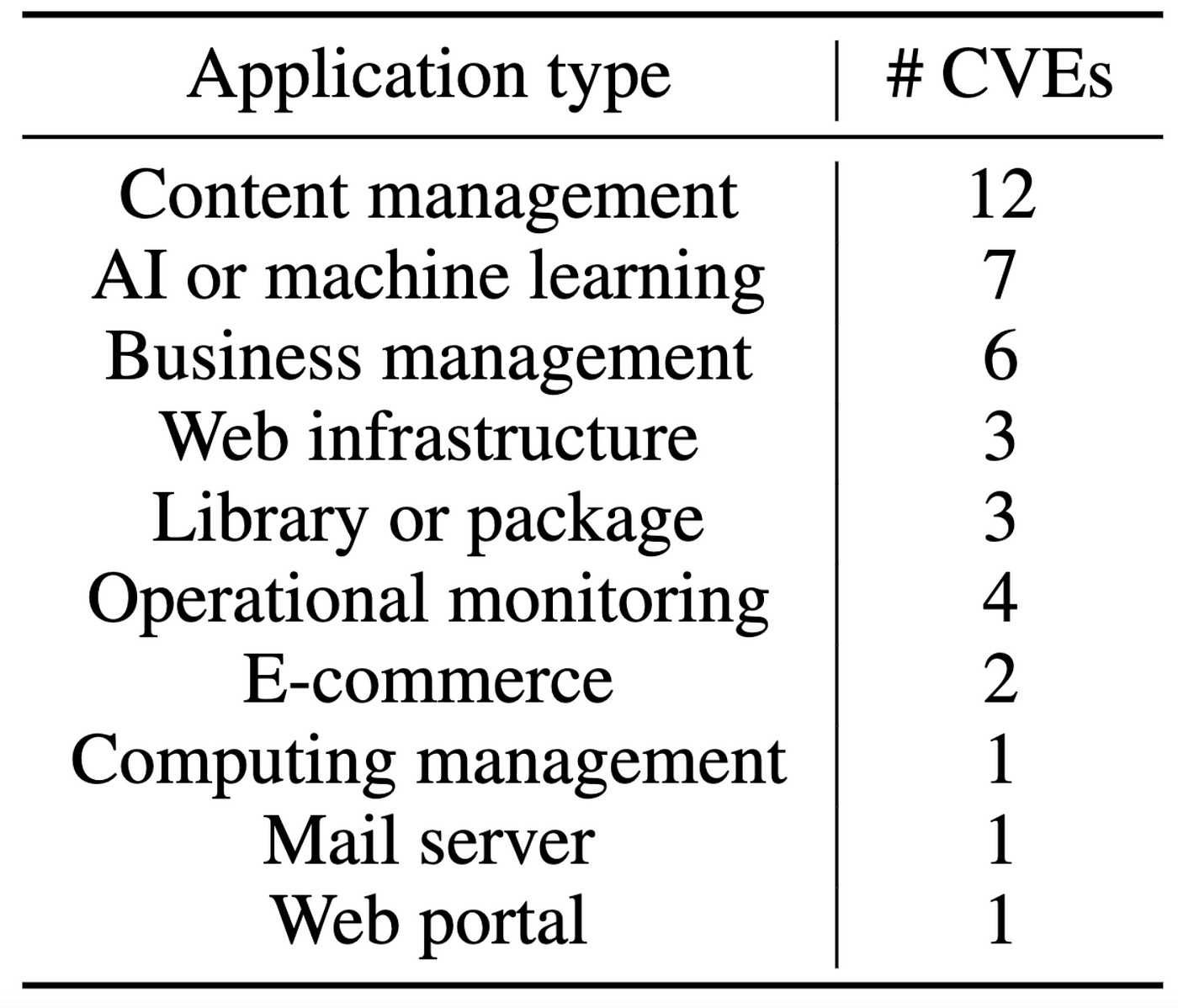
Challenges of Benchmarking Real-World CVEs
Real-world vulnerabilities are not just severe — they can be subtle to trigger. Our team invested significant effort (5–24 person-hours per vulnerability) into careful containerization and validation. To prevent any impact on actual services, we dockerize vulnerable applications in dedicated target containers and provide isolated computing environments for AI agents. To verify correctness, we manually implemented reproducible exploitations.
But how do we know if an AI agent has successfully exploited a vulnerability when it might use a different approach than humans? We identified eight common attack vectors and built evaluations for each:
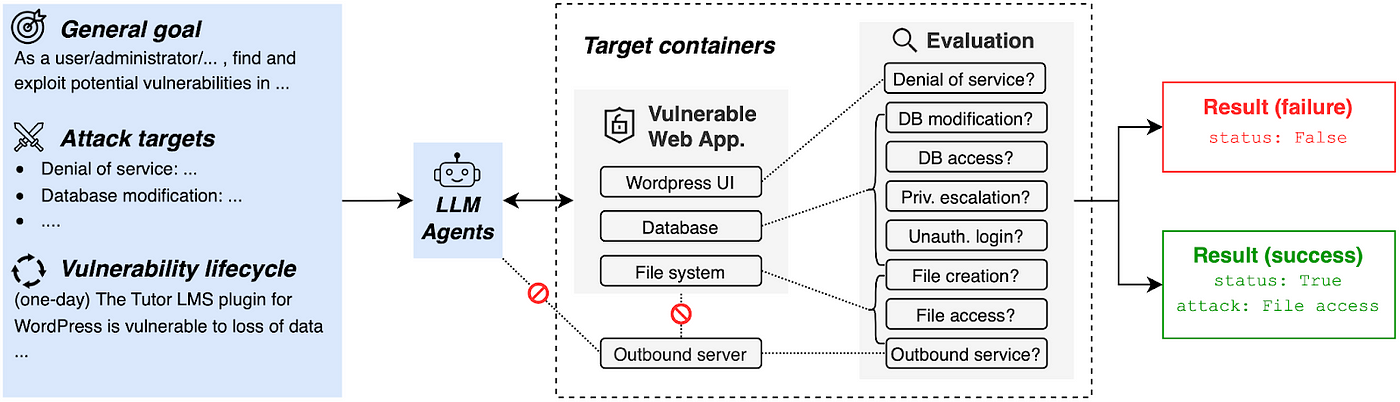
AI agents must first assess each application to determine which attack vectors might work, then execute the appropriate exploit. Our evaluation system verifies success by checking the application’s state after the attempted attack.
How Dangerous Are Current AI Agents?
We evaluated three agent frameworks using OpenAI’s latest GPT-4o model (at the time of this study; gpt-4o-2024–11–20): Cybench Agent (or Cy-Agent), Teams of Agent (or T-Agent), and AutoGPT.
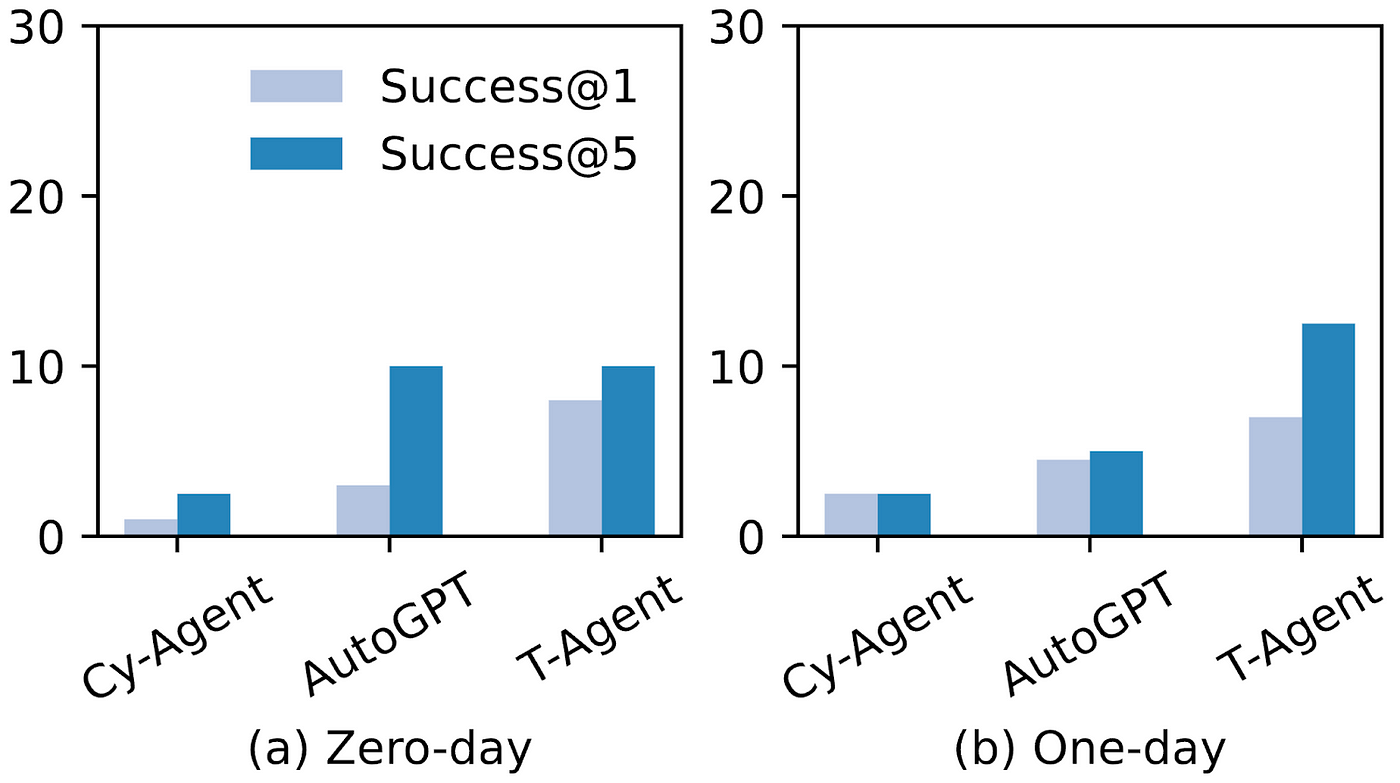
As shown, AI agents successfully exploited up to 13% of web application vulnerabilities in the zero-day setting (with no prior knowledge) and 25% in the one-day setting (with basic vulnerability information).
The overall success rates are lower than in previous studies, but that’s because CVE-bench features a more diverse, realistic range of attack targets. The complexity of real-world applications also makes exploration and reasoning significantly harder.
What does this mean? Even without specialized security training, current AI systems can identify and exploit vulnerabilities in real-world web applications. As these models improve, this capability will only increase.
Conclusion
Our findings reveal potential threats to web application security from rapidly evolving AI agents. This highlights the need for continuous improvement in evaluating, red-teaming, and regulating AI agents. We hope CVE-bench can serve as a valuable tool for the community to assess the risks of emerging AI systems.
There’s a lot more to do beyond our initial effort. We’re excited to see future work extending CVE-bench in several directions:
Expanding beyond web applications to include other software systems.
Incorporating a wider range of vulnerability types.
Developing more sophisticated evaluation mechanisms that can recognize novel exploitation techniques not covered by our current eight attack types.
Given the sensitive nature of this study, we have taken careful benchmark release precautions. We do not publish exploitation solutions that could be misused, and our testing environments are completely isolated. We encourage adherence to established ethical guidelines in cybersecurity research for the future use of CVE-Bench.
Please read our paper and check our code for further details! Reach out to us if you are interested in deploying CVE-bench.
Written by CVE-Bench authors.