
ELT-Bench: Evaluating AI Agents on Automating Data Pipelines

As cloud data warehouses get increasingly popular and storage costs fall, data engineers are increasingly adopting Extract-Load-Transform (ELT) pipelines to integrate and transform data from diverse sources efficiently. However, data engineers must handle various data formats and write complex transformation queries to build ELT pipelines, a task that previous studies estimate practitioners spend over 60% of their time.
AI Agents have recently emerged as a promising approach for tackling real-world challenges in diverse areas, including software engineering, web browsing, and data science and engineering.
Can AI agents also help reduce the engineering effort spent on developing ELT pipelines, enabling data teams to focus more on extracting meaningful insights from data? We created a new benchmark to provide insights into this question. We found existing agents struggled with complex data engineering tasks, achieving only a 3.9% success rate, indicating significant room for improvement.
In this blog post, we’ll dive into our benchmark and our experimental results. Please read our paper and check out the code as well!
Introducing ELT-Bench: The First End-to-End Benchmark in Data Engineering
Building an end-to-end ELT benchmark that simulates real-world data engineering workflows poses several challenges. (1) The number of publicly available ELT projects is limited due to privacy constraints. (2) It requires setting up environments to store data in different formats. (3) Ensuring reproducibility and correctness requires carefully labeling the ground truth and thoroughly verifying pipeline workflows.
To address these challenges, we built ELT-Bench, the first comprehensive benchmark designed to assess AI agents’ capability in building end-to-end ELT pipelines from scratch. ELT-Bench comprises 100 constructed pipelines.
We spent approximately 3 to 5 hours of manual effort per pipeline on environment setup, annotation, and verification. To mirror realistic data engineering workflows, ELT-Bench provides an environment featuring diverse data sources and widely used data tools.
ELT-Bench challenges AI agents to break down the sophisticated workflow into manageable subtasks, interact with databases and data tools, generate code and SQL queries, and orchestrate each pipeline stage.
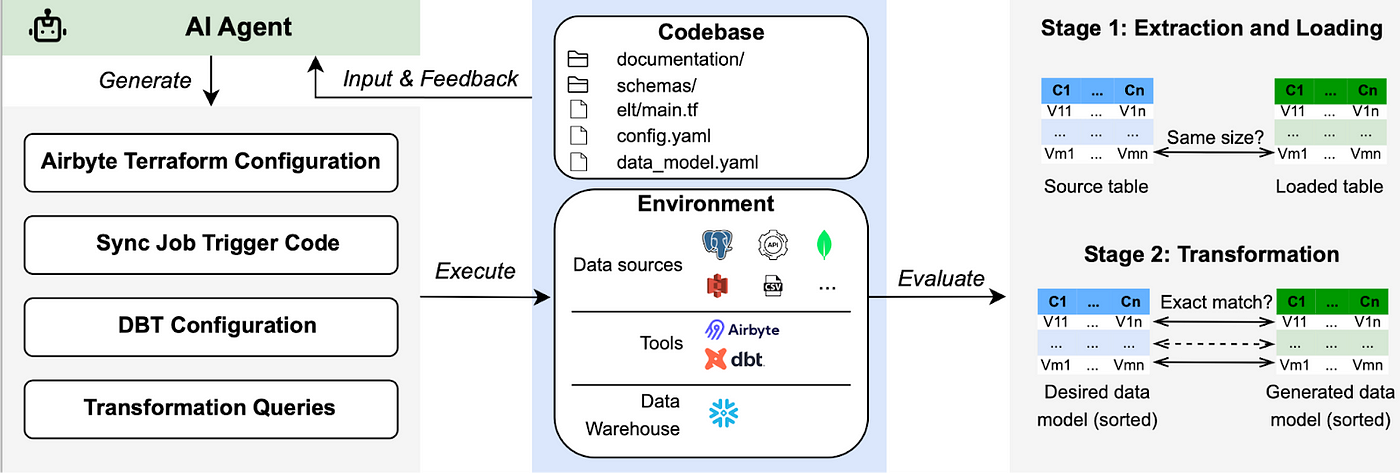
Current AI Agents Struggle: Low Success Rates, High Costs
We evaluated two popular code agent frameworks, Spider-Agent and SWE-Agent, across six popular LLMs (GPT-4o, Claude-3.5-Sonnet, Llama-3.1–405B-Instruct, Qwen2.5-Coder-32B-Instruct, DeepSeek-R1, and Claude-3.7-Sonnet with extended thinking). To measure the effectiveness of these AI agents, we adopted four evaluation metrics:
SRDEL: The proportion of ELT pipelines with complete data extraction and loading.
SRDT: The proportion of correctly generated data models among all data models.
Average cost: The average cost incurred by the AI agent per instance.
Average steps: The mean number of steps executed by the agent per instance.
Our evaluation reveals that current AI agents struggle significantly when performing tasks on the ELT-Bench. We summarized the experimental results in the following table.
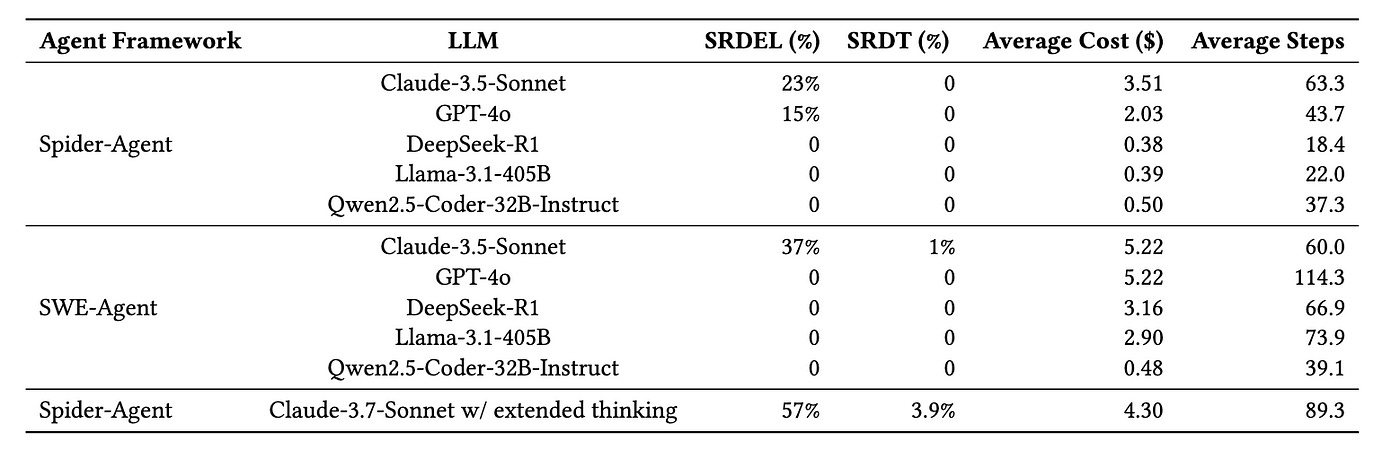
Notably, the top-performing agent, Spider-Agent Claude-3.7-Sonnet with extended thinking, achieves a success rate of 57% in the data extraction & loading stage but only a success rate of 3.9% in the data transformation stage. On average, Spider-Agent Claude-3.7-Sonnet consumes $4.30 and requires 89.3 execution steps per task. Moreover, all tested agents powered by open-source LLMs fail to complete any tasks.
Overall, our findings highlight the significant challenges posed by the ELT-Bench. This underscores the need for more advanced AI agents to alleviate the substantial manual workload in ELT pipeline development. For a detailed error analysis and further insights, please read our paper. Our benchmark is also open-source and available here.
Conclusion
ELT-Bench exposes several key shortcomings of current AI agents when developing ELT data pipelines:
Reasoning limitations: Agents struggle to write complex transformation SQL queries based on natural language descriptions to convert raw data into analytical data models.
Orchestration Complexity and High Costs: Current agents require intensive interaction steps and high computational resources to build ELT pipelines.
Please see our paper and code if you are interested in exploring challenges that AI agents currently face or evaluating your agent on ELT-Bench!
Written by Tengjun Jin, Yuxuan Zhu, and Daniel Kang