
Claude 4.5 Opus Solves CORE-Bench — But Not REPRO-Bench

In our ACL 2025 paper, we introduced REPRO-Bench (GitHub), a benchmark designed to evaluate whether AI agents can accurately assess the reproducibility of social science research papers, and showed that existing AI agents struggled significantly when powered by GPT-4o. In this blog post, we revisit REPRO-Bench with the recently released models (Claude 4.5 Opus and GPT-5.2). We find that although these models achieve significant improvements on a wide range of tasks, and CORE-Bench solved with Claude 4.5 Opus, they still perform poorly on REPRO-Bench. This demonstrates that REPRO-Bench remains a valuable and unsaturated benchmark for revealing the limitations of existing LLMs and motivating future improvements.
We evaluated CORE-Agent and REPRO-Agent, the two best-performing agents with GPT-4o, on REPRO-Bench using Claude 4.5 Opus and GPT 5.2 + Thinking. Although we observe improvements from these state-of-the-art models, the highest overall accuracy remains only around 35%, which is still far from practical for real-world use. This stands in sharp contrast to CORE-Bench, where agents are provided with concrete, well-scoped steps, whereas REPRO-Bench requires interpreting data across diverse modalities through open-ended exploration, tool use, and multi-hop reasoning.
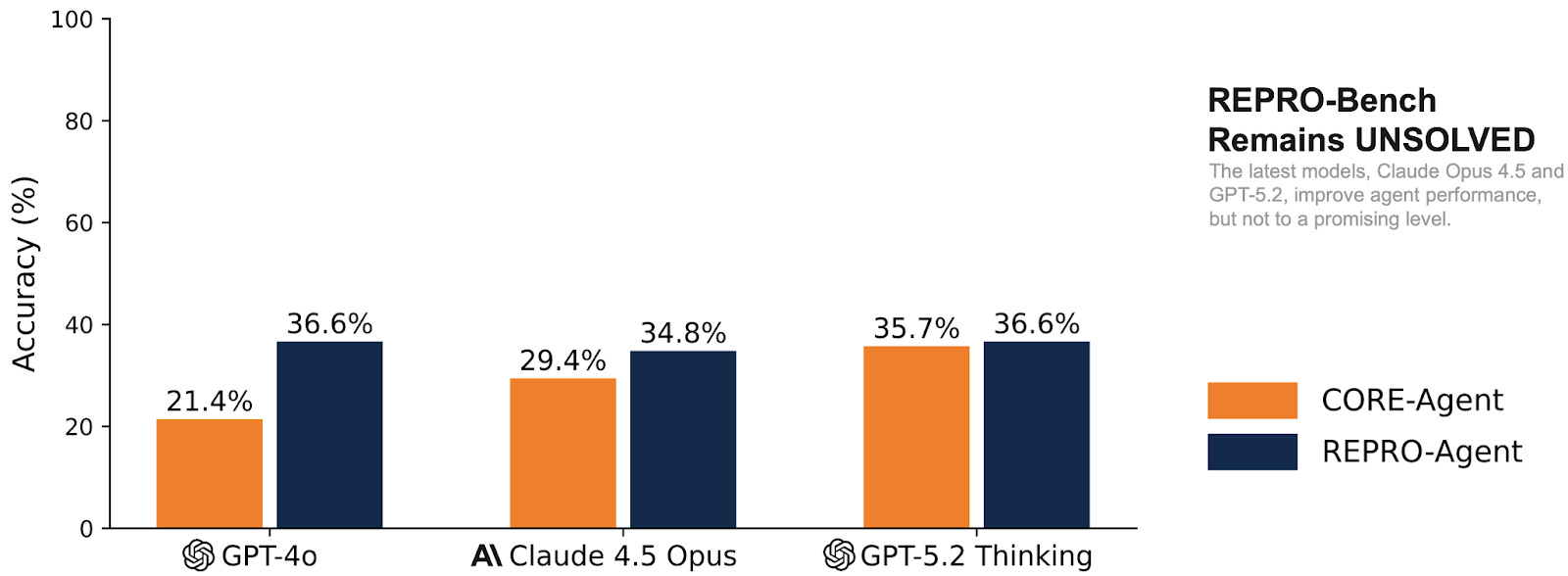
Our results show a substantial improvement from 21.4% (GPT-4o) to 35.7% (GPT-5.2) for CORE-Agent. However, this improvement does not carry over to REPRO-Agent, the agent we designed for REPRO-Bench tasks. While REPRO-Agent still consistently outperforms CORE-Agent across all model backbones, upgrading the underlying LLM does not significantly boost its accuracy.
Interestingly, REPRO-Agent + GPT-4o still outperforms CORE-Agent + GPT-5.2 and CORE-Agent + Claude 4.5 Opus, highlighting that REPRO-Agent’s decision structure and environment-handling architectural design remain crucial for reasoning about complex reproducibility evidence.
We further examine accuracy by ground-truth reproducibility score. GPT-5.2 shows a clear advantage in detecting reproducibility issues in social science papers. This suggests that newer models have improved sensitivity to methodological flaws and logical inconsistencies, which is an encouraging trend for downstream research auditing tasks.
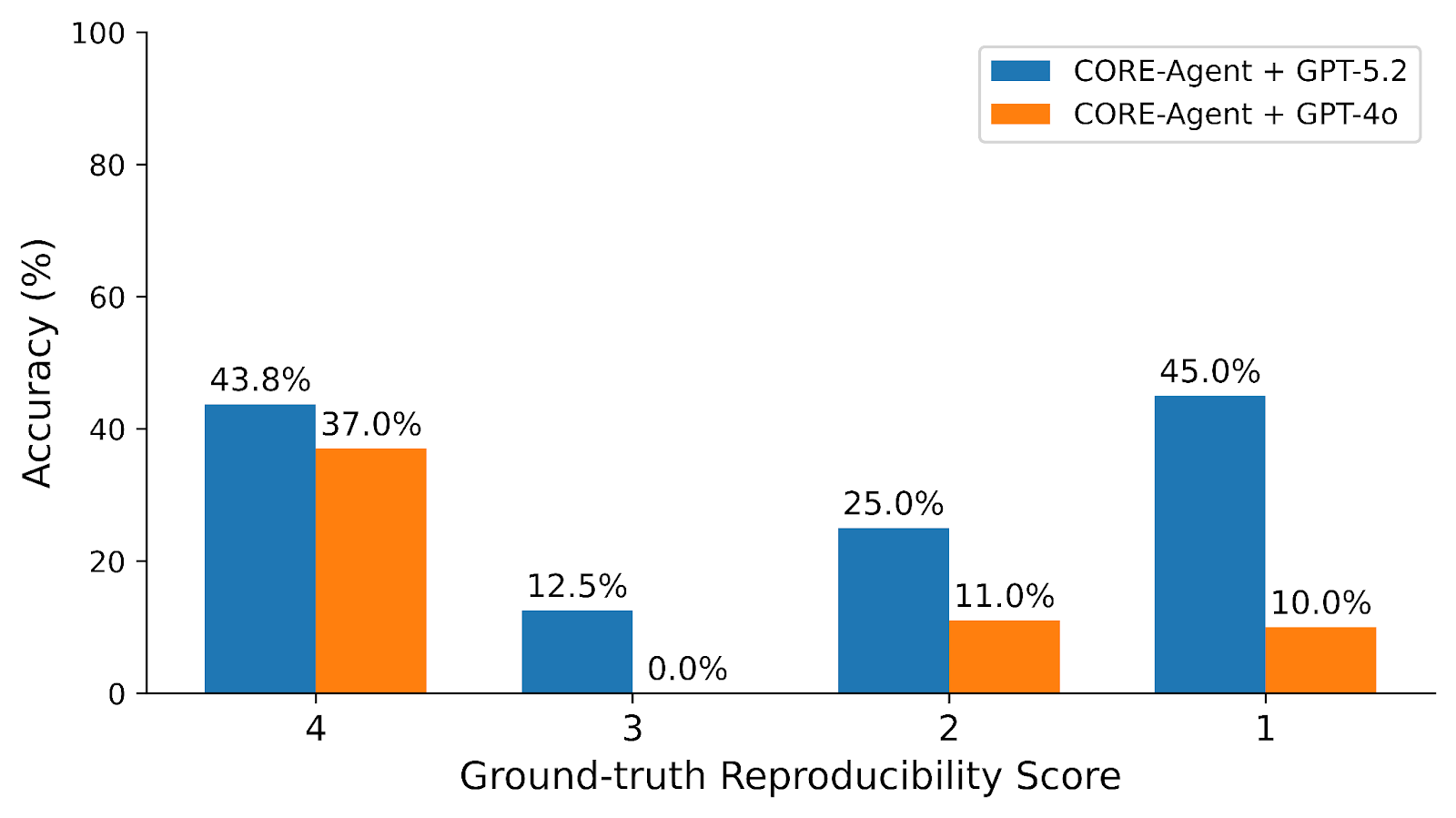
Our findings strengthen our claim that REPRO-Bench represents a substantially harder task set that requires multi-step evidence gathering, reading code and data, interpreting methodology, and synthesizing findings. Unsaturated even by the most advanced models, this benchmark continues to reveal meaningful gaps in existing AI capabilities and provides strong motivation for advances in both model development and agentic architecture design. Check out REPRO-Bench here!