
Accelerating Analytical Joins on Unstructured Data

Semantic joins over unstructured data have become essential to modern data analytics. Today, e-commerce business analysts track competitors’ pricing data by matching and aggregating products from multiple datasets ranging from thousands to millions of records, Similarly, to identify high-risk paths in the supply chain supply-chain analysts reconcile records across multiple tiers of suppliers, where each tier logs shipments, components, and origins in its own narrative format.


To process the complex semantic joins accurately, researchers leverage deep learning methods as an oracle. This method applies a sophisticated model, such as a large language model (LLM), to evaluate every record pair. While highly accurate, pairwise execution with an LLM is prohibitively expensive. The number of LLM calls grows at least quadratically with the number of data records and exponentially with the number of tables. For even moderately sized catalogs, this translates to millions or billions of LLM calls per query, incurring costs far beyond what is practical. For example, performing a semantic join on the Magellan Company dataset costs $43K with GPT-4o mini using the SOTA prompt.
To accelerate such analytical join queries on unstructured data, we propose Blocking-Augmented Sampling (BaS), adaptively orchestrating blocking (executing an oracle only on highly likely pairs) and sampling (unbiased estimation of the population) based on the failure modes of semantic embeddings. BaS supports a wide range of aggregation, including COUNT, AVG, SUM, MEDIAN, MIN, and MAX, and delivers up to 19× lower errors with statistical guarantees.

Balance Efficiency and Accuracy with Blocking-Augmented Sampling
To avoid evaluating every single pair of records, prior data systems have developed two approximation methods: sampling and blocking. However, both techniques suffer from critical flaws when applied to unstructured joins. Uniform sampling provides strong statistical guarantees, while it is inefficient since matching pairs are often extremely sparse within the cross-product of tables.
Conversely, embedding-based blocking uses fast, lightweight embedding models to calculate similarity scores, filtering out any pairs that fall below a certain threshold. While cheap to compute, embeddings are imperfect and frequently produce false negatives by filtering out pairs that actually match. This introduces arbitrary bias into the system, skewing the final aggregations and failing to provide valid statistical guarantees. Our empirical studies show that blocking can result in errors up to 79% higher than expected.
We introduce Blocking-Augmented Sampling (BaS) to combine the best of both worlds and mitigate their drawbacks using adaptive orchestration. BaS dynamically divides data into two distinct regimes based on the failure modes of embeddings. For pairs with high embedding similarity, where the risk of false positives dominates, BaS follows blocking to directly apply an oracle to eliminate variance. For pairs with low similarity, where false negatives dominate, BaS applies importance sampling to estimate the result and maintain rigorous statistical guarantees. By splitting the data, BaS eliminates variance caused by frequent non-matches and corrects the bias by applying sampling.
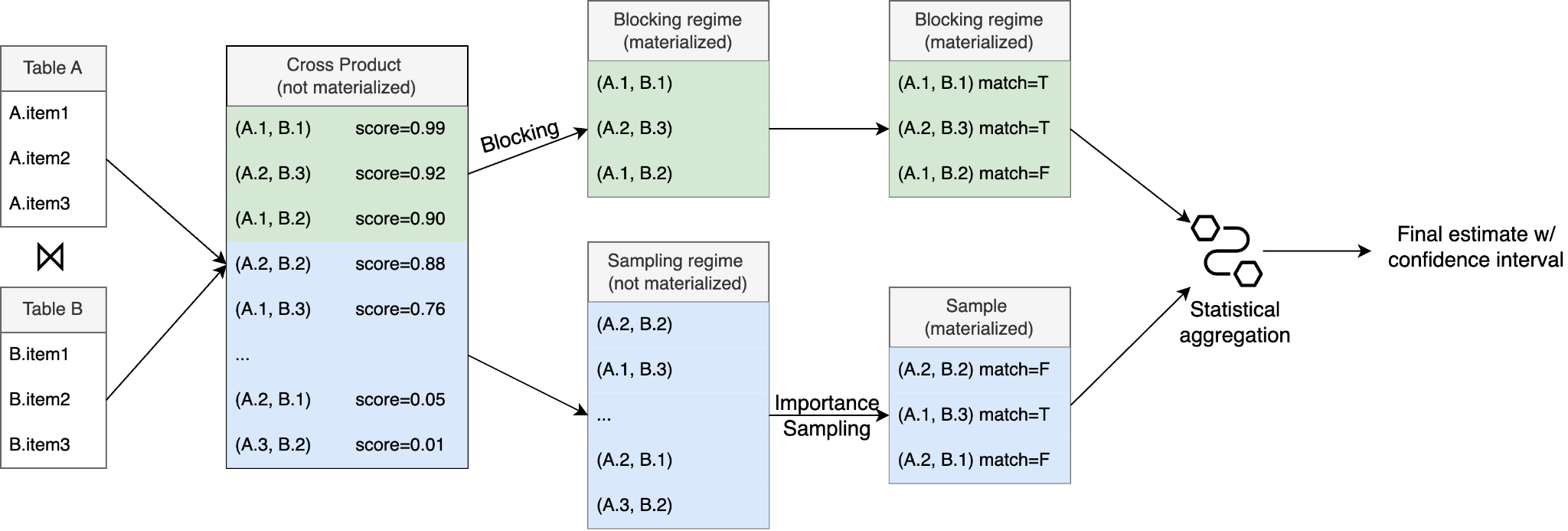
Adaptive Data Allocation with Statistical Guarantees
The core technical challenge of making BaS work is determining the optimal boundary between the blocking and sampling regimes given a fixed budget for ML executions. Empirically, we find that choosing the wrong boundary is disastrous. Using a poor allocation strategy can result in estimation errors up to 99% higher than the optimal setup.
To solve this, we develop a novel adaptive allocation algorithm via two-stage stratified sampling. Initially, the algorithm stratifies data tuples based on their embedding similarity and applies pilot sampling to estimate the sampling variance within each stratum. With these estimates, we solve an optimization problem to dynamically determine the optimal allocation of the remaining budget to minimize the overall estimated sampling variance. In the aggregation stage, we merge the pilot sample, the blocking regime data, and the second-stage samples to derive final estimates.
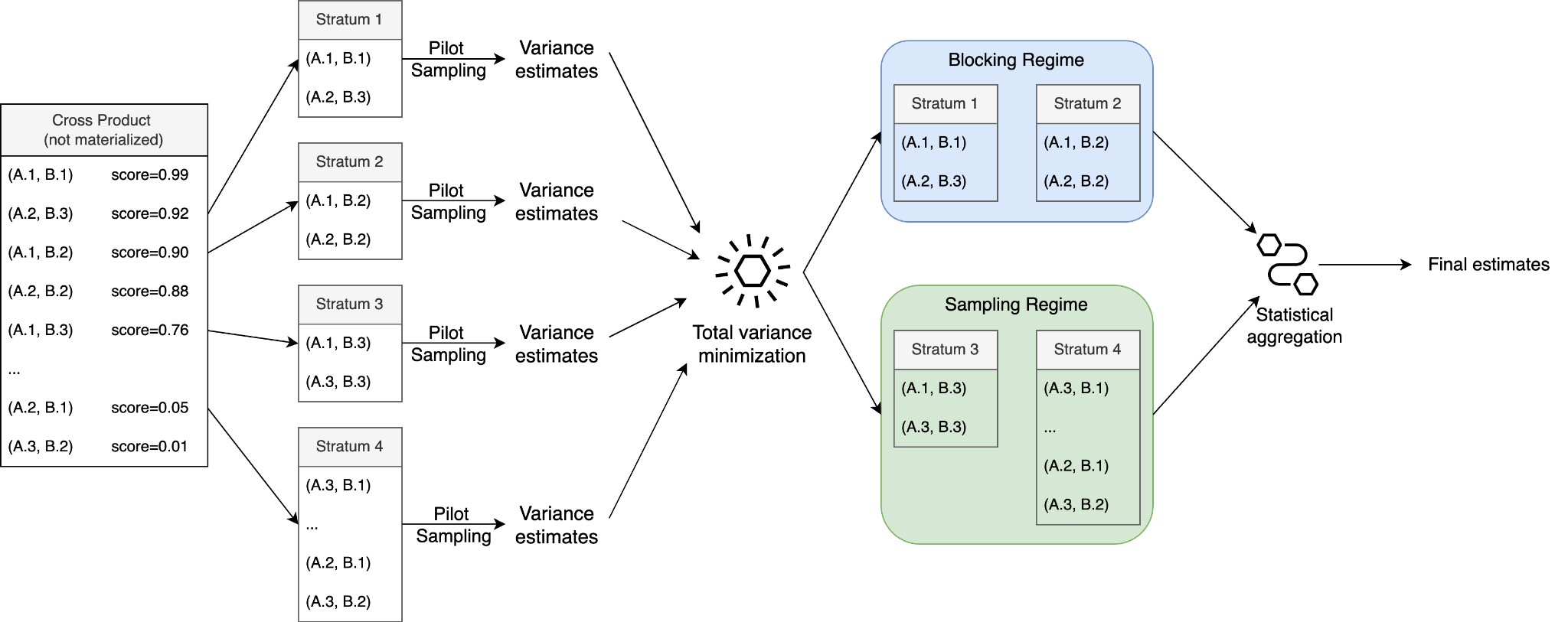
Since merging data from two dependent stages breaks data independence, standard confidence intervals fail to hold. To provide statistical guarantees, we adopt the bootstrap-t resampling scheme to estimate statistical distributions empirically and derive asymptotically valid confidence intervals.
Extensions. BaS with adaptive allocation is highly extensible and can natively handle ratio estimators for AVG, alongside extreme estimators (MIN and MAX), quantile estimators (MEDIAN), GroupBy aggregation, and selection queries with statistical guarantees. We defer extension details to our paper.
BaS Achieves Up to 19× Error Reduction with Statistical Guarantees
We implemented BaS in a prototype system, JoinML, and rigorously evaluated it across 16 datasets covering text, image, and bimodal modalities. We compared with various baselines, including:
State-of-the-art approximate analytical query processing algorithms: ABae and BlazeIt.
State-of-the-art approximate selection query processing algorithms: SUPG and LOTUS.
Standard sampling algorithms: uniform sampling and importance sampling (implemented as weighted wander join or WWJ).

On linear aggregators, BaS achieves lower root mean squared error by 1.5--19.5× compared to uniform sampling, 1.0--17.2× compared to WWJ, and 1.2--17.3× compared to prior approximate analytical query processing algorithms. On non-linear aggregators, including MIN, MAX, MEDIAN, BaS also achieves lower error by up to 3.0× than sampling, while ABae and BlazeIt do not support them. Furthermore, compared to sampling algorithms, BaS yields up to 2.1× lower error on a GroupBy query with a COUNT aggregate.

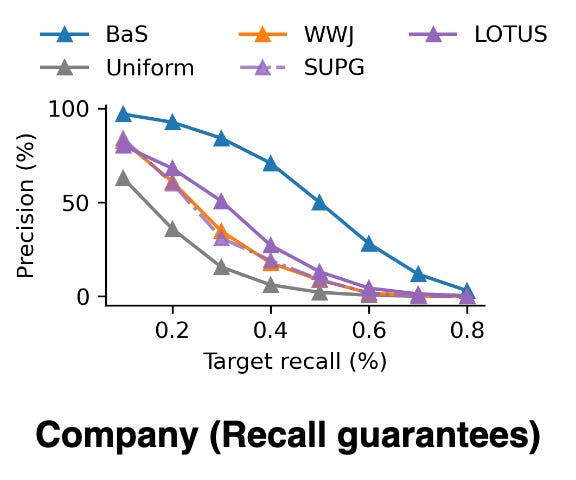
Beyond aggregations, BaS also significantly improves selection queries. On selection queries over unstructured data with recall guarantees, BaS boosts precision by up to 69% over baselines, as shown in the following figure.
The Future of Unstructured Data Analytics
As the capabilities of foundation models scale, the desire to run complex, multi-table semantic analytics on unstructured data is growing. Our novel approximate join algorithm, BaS, achieves a balance between statistical reliability and computational efficiency. Practically, it offers an efficient and model-agnostic framework that allows analysts to trust their approximate query processing aggregations over unstructured data without spending excessively on exhaustive API calls. Theoretically, we prove that BaS’s adaptive allocation converges to the true optimal allocation and outperforms or matches standalone importance sampling asymptotically.
For more information, please check our paper (including theoretical analyses) and our code!